
8 octobre 2025

Introduction : pourquoi apprendre aux machines à lire l’écriture manuscrite?
Chaque jour, des millions de notes, formulaires ou documents manuscrits circulent encore dans nos vies. À l’échelle de l’histoire, des millions de pages d’archives dorment dans les bibliothèques et les musées. Pouvoir les lire automatiquement n’est pas seulement un gain de temps : c’est un enjeu majeur pour préserver le patrimoine, automatiser les tâches administratives et améliorer l’accessibilité.
Pourtant, enseigner à une machine à lire l’écriture humaine est une tâche redoutable. Contrairement aux caractères imprimés, l’écriture manuscrite varie énormément d’une personne à l’autre : certains écrivent lisiblement, d’autres griffonnent rapidement, parfois les mots se chevauchent, les lignes s’inclinent, ou les lettres se déforment. Pour une IA, c’est un peu comme devoir déchiffrer chaque jour l’écriture d’un nouveau médecin!

Figure 1 – Du manuscrit ancien au numérique
Les défis de la reconnaissance manuscrite
Depuis plusieurs décennies, les chercheurs tentent de relever ce défi. Mais les approches classiques ont montré leurs limites. Trois obstacles majeurs subsistent :
- La variabilité des styles d’écriture : chaque scripteur a sa « signature » unique.
- Le besoin de données annotées : la plupart des modèles ont besoin de millions d’exemples correctement transcrits pour apprendre.
- Le coût en calcul : les architectures performantes nécessitent souvent des serveurs puissants, ce qui freine leur utilisation dans des environnements réels ou sur des appareils légers.
Notre approche : une IA qui apprend comme un humain
Pour surmonter ces obstacles, nous avons développé une méthode innovante appelée Efficient HTR. Son originalité repose sur trois piliers :
- Apprentissage autosupervisé : notre système apprend d’abord tout seul, sans avoir besoin d’énormes bases de données annotées. Concrètement, il reçoit des textes manuscrits partiellement masqués et doit deviner les parties manquantes, un peu comme un enfant qui devine un mot dans une phrase incomplète. Ce processus l’entraîne à comprendre à la fois les détails des lettres et la structure globale des paragraphes.
- Une architecture hybride : nous combinons deux grandes familles d’outils de l’intelligence artificielle.
- Les réseaux de neurones convolutifs (CNN), experts pour détecter les détails visuels comme les courbes ou les points.
- Les Transformeurs, qui excellent à comprendre le contexte global, par exemple la logique d’une phrase.
Ensemble, ils permettent à la machine de « zoomer » sur une lettre tout en gardant une vue d’ensemble sur le paragraphe.
- Un décodeur intelligent : au lieu d’obliger le système à découper le texte ligne par ligne, notre modèle peut lire un paragraphe entier d’un seul coup d’œil, puis le transformer directement en séquence de caractères. Cela rend la lecture plus fluide, plus rapide et plus proche de la façon dont un humain perçoit un texte.
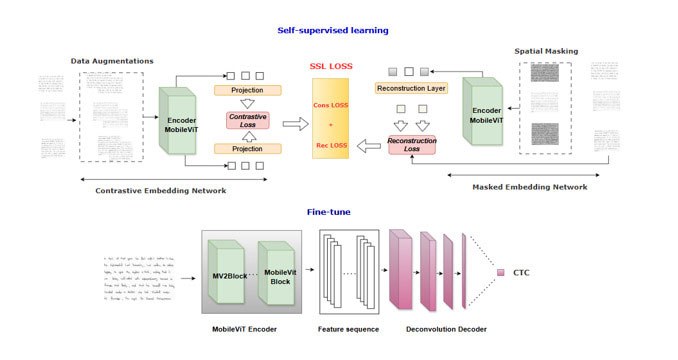
Figure 2 – Le système proposé pour la lecture manuscrite. L’IA apprend d’abord seule à reconnaître les formes et les structures générales de l’écriture (phase d’autoapprentissage), puis elle est entraînée à transformer les images de texte manuscrit en séquences lisibles (phase d’entraînement supervisé). Cette approche permet de lire directement des paragraphes complets sans découpage préalable.
Des résultats prometteurs
Nous avons testé notre méthode sur deux bases de données de référence :
- IAM, qui contient des textes manuscrits en anglais.
- RIMES, qui rassemble des courriers manuscrits en français.
Résultat : notre système lit avec une précision très compétitive tout en étant plus léger et plus rapide que la plupart des approches existantes. Autrement dit, il n’a pas besoin d’ordinateurs géants pour fonctionner.
Ces performances sont possibles grâce à l’apprentissage autosupervisé, qui réduit la dépendance aux données annotées, et à la combinaison équilibrée entre détails locaux et compréhension globale.
Retombées concrètes
Les applications de cette recherche sont nombreuses et concernent aussi bien le monde scientifique que notre quotidien :
- Conservation du patrimoine : des archives manuscrites, parfois vieilles de plusieurs siècles, pourraient être transcrites automatiquement pour être accessibles en ligne.
- Automatisation administrative : formulaires remplis à la main, courriers ou notes médicales pourraient être traités plus rapidement, réduisant le temps perdu dans les tâches répétitives.
- Accessibilité : une telle technologie pourrait être intégrée à des outils d’assistance pour aider les personnes malvoyantes à accéder à des textes manuscrits.
- Efficacité énergétique : grâce à son architecture légère, notre modèle consomme moins de ressources, ce qui en fait une solution plus écologique et adaptée à des environnements contraints comme les appareils mobiles.
Conclusion : lire aujourd’hui pour préserver demain
Avec Efficient HTR, nous montrons qu’il est possible de concilier précision, efficacité et accessibilité dans la reconnaissance d’écriture manuscrite. Notre approche combine le meilleur des deux mondes : un apprentissage intelligent inspiré de la manière dont les humains complètent les informations manquantes, et une architecture optimisée qui sait à la fois zoomer sur les détails et comprendre le contexte global.
Au-delà des chiffres et des performances, l’objectif est clair : permettre à nos sociétés de mieux lire aujourd’hui pour mieux préserver demain. Qu’il s’agisse d’un manuscrit historique ou d’un simple formulaire, cette technologie rapproche un peu plus l’intelligence artificielle de la compréhension du langage humain dans toutes ses formes.


