
October 8, 2025

Abstract
Handwritten Text Recognition (HTR) remains a fundamental challenge in document analysis, where both accuracy and computational efficiency are required. We present Efficient HTR, a lightweight system designed to achieve strong recognition performance while reducing annotation needs and computational cost. The approach begins with self-supervised pretraining, where the model learns to reconstruct masked regions of handwritten text images, capturing both fine-grained strokes and global paragraph structures. It is then fine-tuned with labels using a hybrid CNN–Transformer backbone that combines local shape modeling with long-range context, and a recurrence-free, segmentation-free decoder that transcribes entire paragraphs in a single pass.
On the IAM (English) and RIMES (French) benchmarks, Efficient HTR achieves 5.76% CER / 14.23% WER and 2.29% CER / 6.88% WER, respectively, while running at ≈32 images/s on a single NVIDIA RTX 3090 GPU with 12M parameters, outperforming or matching strong baselines at lower computational cost. This combination of self-supervision, hybrid context modeling, and efficient paragraph-level decoding reduces reliance on massive labeled datasets, improves throughput, and generalizes across diverse handwriting styles—offering practical benefits for heritage digitization, administrative automation, and assistive technologies.
Introduction: Why Teach Machines to Read Handwriting?
Every day, millions of handwritten notes, forms and documents are still part of our lives. Millions of pages of historical archives lie dormant in libraries and museums. Being able to read them automatically can not only save time, it can also preserve our heritage, automate administrative tasks, and improve accessibility.
Yet, teaching a machine to read human handwriting is a daunting task. Unlike printed characters, handwriting varies greatly from one person to another. Some write legibly, others scribble quickly, sometimes words overlap, lines slant or letters become distorted. For AI, it’s a bit like having to decipher a new doctor’s handwriting every day!

Figure 1 – From ancient manuscripts to digital
The Challenges of Handwriting Recognition
Researchers have been trying to tackle this challenge for many decades. But traditional approaches have their limitations. Three major obstacles remain:
- The diversity of writing styles: each writer has their own unique “signature.”
- The need for annotated data: most models require millions of correctly transcribed examples to learn.
- The cost in computing power: high-performance architectures often require powerful servers, which limits their use in real-world environments or on lightweight devices.
Our Approach: AI That Learns Like a Human
To overcome these obstacles, we have developed an innovative method called Efficient HTR. Its originality is based on three pillars:
- Self-supervised learning: our system first learns on its own, without the need for huge annotated datasets. In practice, it receives partially redacted handwritten texts and must guess the missing parts, like a child guessing a word in an incomplete sentence. This process trains it to understand both the details of letters and the overall structure of paragraphs.
- A hybrid architecture: we combine two main groups of artificial intelligence tools.
- Convolutional Neural Networks (CNNs), which detect visual details such as curves or dots.
- Transformers, which understand the overall context, such as the logic of a sentence.
Together, these enable the machine to “zoom in” on a letter while maintaining an overview of the paragraph.
- A recurrence-free, segmentation-free decoder: instead of forcing the system to process text line by line, our model reads entire paragraphs in a single pass and directly converts them into character sequences. This enables smoother and faster transcription, closer to the way humans perceive written text.
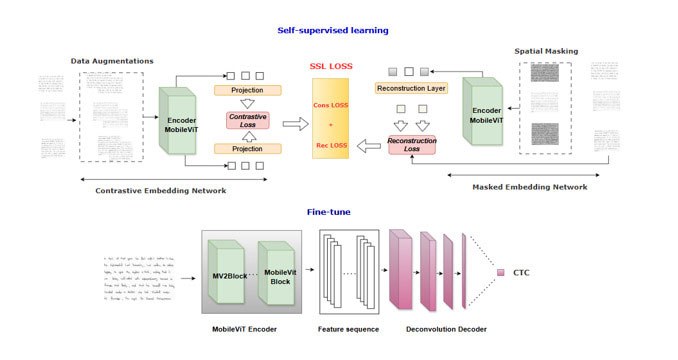
Figure 2 -Proposed system schematic: self-supervised pretraining → supervised fine-tuning → paragraph-level decoder.
The model first trains self-supervised to recognize the general shapes and structures of handwriting (pretraining phase), and is then fine-tuned to transform handwritten text images into readable sequences (supervised training phase). This design enables reading entire paragraphs directly, without prior segmentation.
Promising Results
We evaluated our method on two benchmark datasets:
- IAM (English): 5.76% Character Error Rate (CER) / 14.23% Word Error Rate (WER)
- RIMES (French): 2.29% CER / 6.88% WER
Our model contains ≈ 12M parameters and runs at ≈32 images per second on a single NVIDIA RTX 3090 GPU, making it about 2× faster than TrOCR-base while remaining significantly lighter.
This performance is achieved through self-supervised learning, which reduces dependence on annotated datasets, combined with a hybrid CNN–Transformer backbone that balances local detail extraction with global context modeling.
The current study focuses on Latin scripts (English and French); transfer to non-Latin writing systems remains an open challenge for future work.
Real Benefits
The applications of this research are numerous and touch both the scientific world and our daily lives:
- Preserving our heritage: handwritten archives, some of which are centuries old, could be automatically transcribed and made available on-line.
- Administrative automation: handwritten forms, letters and medical notes could be processed more quickly, reducing time wasted on repetitive tasks.
- Accessibility: Such technology could be integrated into assistive tools to help visually impaired people access handwritten texts.
- Energy efficiency: thanks to its lightweight architecture, our model consumes fewer resources, making it a more environmentally friendly solution that is well suited to limited environments such as mobile devices.
Conclusion: Reading Today to Preserve Tomorrow
This work introduced Efficient HTR (DeconvSSL-Net), a lightweight handwriting recognition system that combines self-supervised pretraining, a hybrid CNN–Transformer backbone, and a recurrence-free, segmentation-free decoder. Our results on IAM (5.76% CER / 14.23% WER) and RIMES (2.29% CER / 6.88% WER) demonstrate that it is possible to achieve strong paragraph-level recognition performance while significantly reducing computational requirements and reliance on large annotated datasets. The model not only matches but in some cases exceeds strong baselines, while offering improved throughput and a smaller footprint—making it well-suited for resource-constrained environments.
At the same time, several challenges remain. The system occasionally struggles with punctuation and case sensitivity, as well as overlapping characters in densely written lines. Furthermore, while our architecture is optimized for Latin-based scripts, its extension to non-Latin alphabets requires additional exploration.
Looking forward, we plan to enhance the framework by incorporating layout-aware tokenization to better handle complex paragraph structures, and by exploring semi- and self-supervised strategies for rapid adaptation to new scripts. We also aim to develop lighter backbones optimized for mobile deployment, enabling efficient recognition on edge devices.
To encourage adoption and reproducibility, we will release our code, training configurations, and scripts, providing the community with a transparent foundation for further research and practical applications in heritage digitization, administrative automation, and assistive technologies.


