
November 19, 2025

Code review is an essential part of modern software development. Yet, not all code changes are treated equally. For example, urgent bug fixes often receive the same attention as cosmetic updates. Traditional tools use rigid keyword-based rules to identify the purpose behind code changes, often leading to misclassification. In this article, we introduce the LLM Change Classifier (LLMCC), an AI-powered tool that uses Large Language Models (LLMs) to understand the intent behind code changes. Tested on three large open-source projects, LLMCC significantly outperforms both rule-based systems and traditional AI models. The tool promises to help developers prioritize their review efforts more effectively and improve software quality.
KEYWORDS: Large Language Models, Modern Code Review, Machine Learning, Change Intent Analysis
Rethinking Code Reviews with AI
Modern software development is a team effort. Before being accepted into a project, new codes undergo a review, where another developer evaluates the changes in order to detect bugs or identify improvements. But not all code changes are created equal. Fixing a critical bug is more urgent than updating documentation or adding a new feature. Unfortunately, most review systems treat all changes the same, which can delay important fixes. This is where Large Language Models (LLMs) come in.
The Limitations of Traditional Classification
Developers can manually tag their code changes with labels such as “bug fix,” “feature,” or “test.” However, this is inconsistent and often skipped. Previous research tried to automate this classification using keyword rules [1]. But this method is too rigid. A code change that improves documentation might include the word “improve,” leading the system to misclassify it as a new feature.
LLMCC: Smarter Classification of Code Changes
To solve the problem, we developed the LLM Change Classifier (LLMCC), a tool that leverages LLMs to understand and classify the intent behind code changes. Unlike traditional methods, LLMCC considers the change title, description, affected files, and even the code differences themselves. It uses Google's Gemini 1.5 Pro [2].
LLMCC operates in zero-shot mode, meaning it doesn't require labeled training data. It can make predictions based purely on its understanding of natural and programming languages.
How LLMCC Outperforms Existing Methods
We evaluated LLMCC using 935 real code changes from three major open-source projects: Android, OpenStack, and Qt. We compared LLMCC’s predictions with traditional heuristics [1], standard machine learning [3], and deep learning models such as BERT [4] and RoBERTa [5].
LLMCC consistently outperformed all other techniques across all projects. It achieved F1-scores up to 33% higher than rule-based approaches, and showed a 77% improvement in MCC as depicted in Figure 1. We can also see in Figure 2 that LLMCC outperformed deep learning algorithms (BERT and RoBERTa). These results highlight LLMCC’s ability to understand both natural language and code.
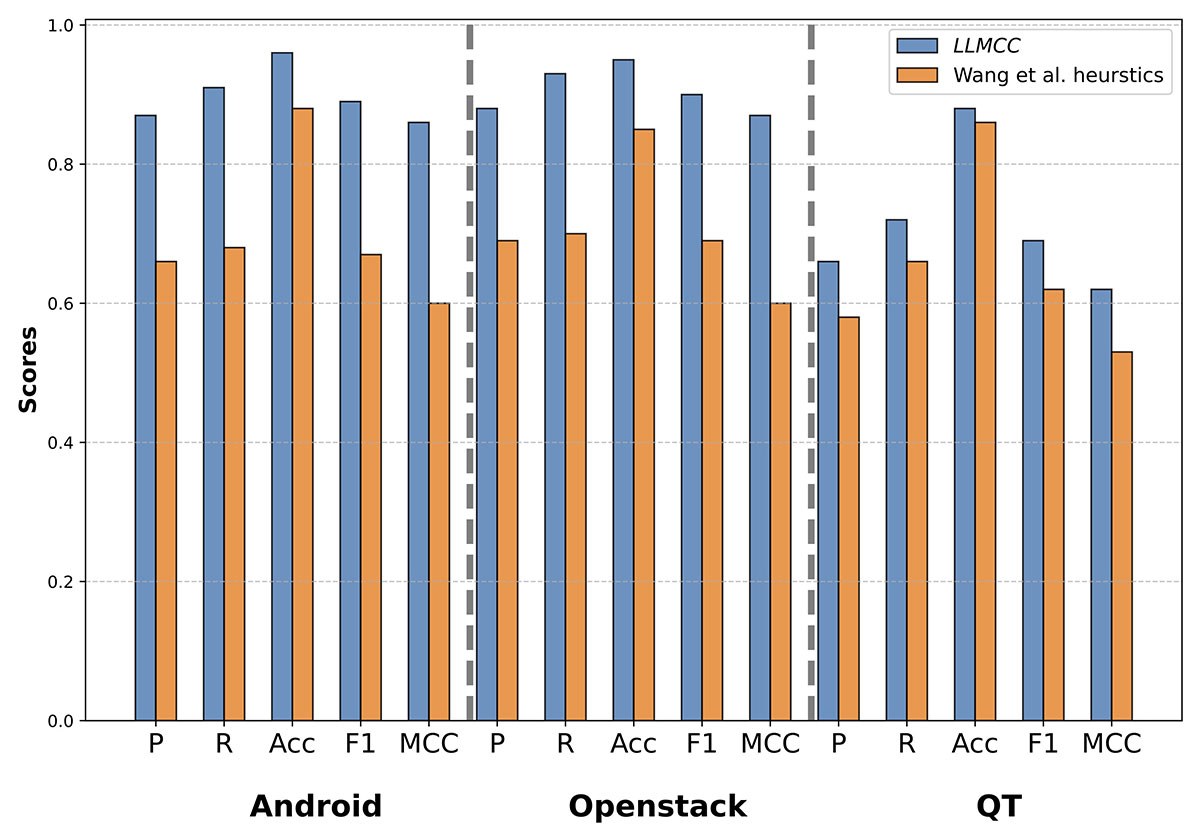
Fig. 1. LLMCC vs Wang et al. heuristics [1].
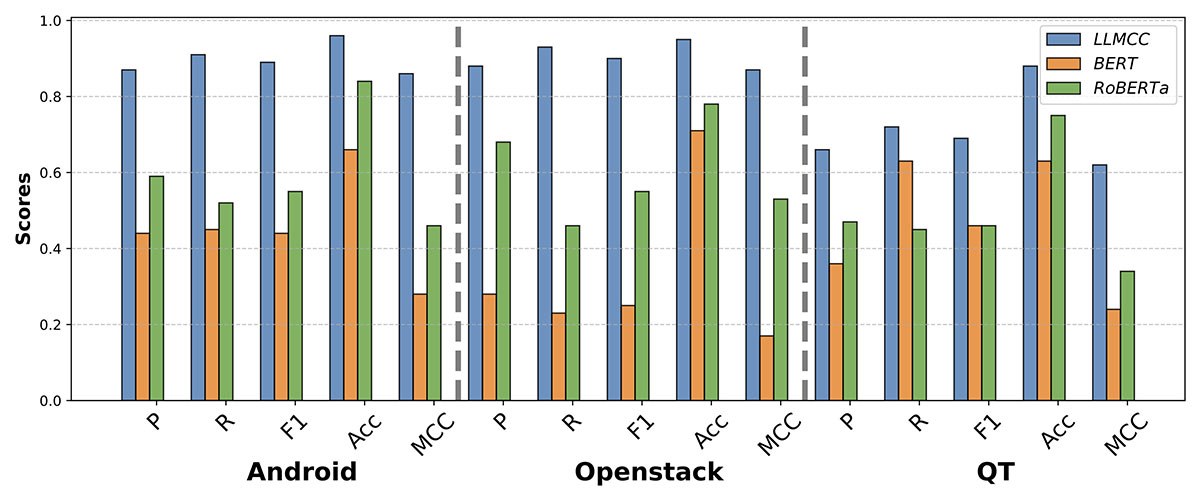
Fig. 2. LLMCC vs BERT and RoBERTa.
Faster Reviews, Better Prioritization
LLMCC streamlines the code review process by enabling better prioritization. Rather than treating all code changes equally, reviewers can focus on urgent or impactful updates. For example, a critical fix can be identified and reviewed faster, reducing the risk of delays.
Future work will include experimenting with different LLMs (open-source vs proprietary), improving prompt engineering [6], and studying real-world integration into development workflows.
Conclusion: Towards Smarter Code Reviews
Code review is vital to software development, but current methods can be slow and inconsistent. With LLMCC, we demonstrate that large language models can understand code and its context, allowing accurate classification of change intent, saving time and improving software quality.
Additional Information
Oukhay, I. Chouchen, M. Ouni A. Fard Hendijani F. On the Performance of Large Language Models for Code Change Intent Classification. (SANER 2025, ERA track)
Chouchen, M. Oukhay, I. Ouni A. Learning to Predict Code Review Rounds in Modern Code Review Using Multi-Objective Genetic Programming (GECCO 2025)
REFERENCES
[1] S. Wang, C. Bansal, and N. Nagappan, “Large-scale intent analysis for identifying large-review-effort code changes,” Information and Software Technology, vol. 130, p. 106408, 2021.
[2] T. G. et al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,” arXiv preprint arXiv:2403.05530, 2024.
[3] A. Hindle, D. M. German, M. W. Godfrey, and R. C. Holt, “Automatic classification of large changes into maintenance categories,” in ICPC, 2009.
[4] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” NAACL, 2019.
[5] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
[6] M. Chouchen, N. Bessghaier, A. Ouni, and M. W. Mkaouer, “How do software developers use chatgpt? an exploratory study on github pull requests,” in MSR, 2024.


