
Amélioration de la vitesse d'apprentissage machine

Achetée sur Istock.com. Droits d’auteur.
L’apprentissage machine (ML) s’est démocratisé. Parmi les avantages du ML, notons la possibilité d’extraire des modèles à partir de données avec un minimum d’intervention humaine. Obtenir un modèle nécessite une puissance de calcul haute densité, puissance allant bien au-delà de la capacité des processeurs classiques comme les unités centrales de traitement (CPU). De tels processeurs ralentissent le ML et le rendent inabordable. Pour améliorer les performances du ML, nous proposons une nouvelle approche de conception hybride alliant processeurs graphiques (GPU), réseaux prédiffusés programmables par l’utilisateur (FPGA) et CPU dans un même système de ML. Cette approche offre des avantages énormes par rapport aux architectures ML standards. Mots clés: Apprentissage machine, GPU, FPGA, calcul haute performance, réseau de neurones
Améliorer la puissance de calcul grâce à des GPU et FPGA en parallèle
Aujourd’hui, l’apprentissage machine (ML) est en plein essor et de nombreuses applications en émergent comme l’IA du jeu, la conduite autonome, l’aide au diagnostic, les transactions automatiques et la reconnaissance faciale. Ces applications visent à améliorer considérablement notre qualité de vie et le rendement au travail. Toutefois, on n’a rien pour rien. La figure 1 illustre un réseau de neurones profonds (DNN) simple et général, fondement de la plupart des réseaux de neurones (NN) complexes. La figure montre également comment se calcule une valeur d’un nœud sur une couche cachée, soit par multiplications et additions de matrices. Pour un unique nœud, le calcul peut paraître simple, mais étendu sur l’ensemble du NN, qui compte généralement des dizaines, des millions ou des milliards de nœuds, la situation est bien différente. Ce système nécessite une grande puissance de calcul haute densité en raison de sa complexité.
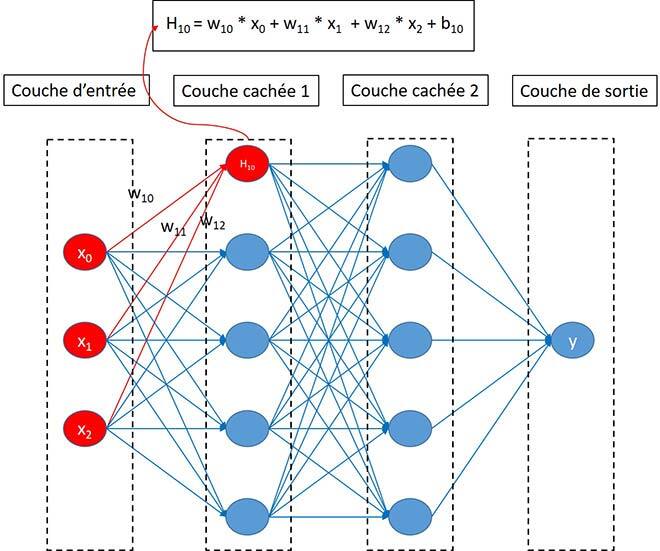
Figure 1 Exemple de calcul DNN.
Pour faire un tel travail, il faut des processeurs puissants. Selon l’analyse qui précède, les ML sont principalement composés d’opérations matricielles massives, lesquelles peuvent toutes être effectuées en parallèle. Par conséquent, des périphériques paramétrables, dotés de puissants processeurs et placés en parallèle sont nécessaires. La figure 2 illustre les principaux périphériques informatiques de l’heure. Les processeurs classiques comme les CPU, qui comptent peu de cœurs de calcul et exécutent des commandes en séquence, ne peuvent répondre au besoin de calcul haute densité. Les processeurs graphiques (GPUDéf. : « Un processeur graphique, ou GPU (de l’anglais Graphics Processing Unit), est un circuit intégré présent la plupart du temps sur une carte graphique (…) et assurant les fonctions de calcul de l’affichage. » Wikipedia https://fr.wikipedia.org/wiki/Processeur_graphique), dont la structure est hautement parallèle, sont idéals pour le calcul en parallèle. Les matrices FPGADéf. : « Outil de placement-routage automatique qui fait correspondre le schéma logique voulu par le concepteur et les ressources matérielles de la puce. » Wikipedia
https://fr.wikipedia.org/wiki/Circuit_logique_programmable#FPGA comptent un grand nombre de blocs logiques configurables pour effectuer des fonctions comme les additions et les multiplications. Si on ne tient pas compte du coût, le FPGA est celui qui offre le plus de capacité de calcul parallèle. On peut non seulement décider de la façon de répartir les tâches de calcul sur les ressources, mais aussi configurer chaque bloc logique fonctionnel pour obtenir les meilleures performances possibles. Si le budget est limité et que les performances extrêmes ne sont pas requises, on peut choisir le GPU. Les GPU ont d’énormes unités de calcul parallèle prêtes à l’emploi, qui peuvent être programmées directement.
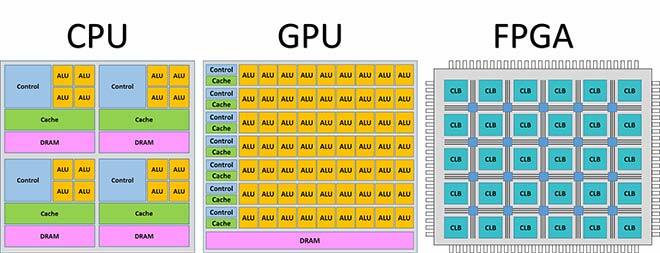
Figure 2 Architectures CPU, GPU et FPGA.
À l’heure actuelle, beaucoup de travail a porté sur le seul recours au GPU pour accélérer le ML (Raina, Madhavan et al. (2009), Bergstra, Bastien et al. (2011), Bergstra, Bastien et al. (2011), Potluri, Fasih et al. [2011]), ou le FPGA pour accélérer la phase d’inférence d’un sytème ML (Motamedi, Gysel et al. (2016), Qiu, Wang et al. (2016), Nagarajan, Holland et al. (2011), Nagarajan, Holland et al. [2011]). Toutefois, selon nos recherches (Liu, Ounifi et al. (2018), Liu, Ounifi et al. [2019]), il est préférable de combiner GPU et FPGA pour mettre en œuvre le ML de façon à obtenir les meilleures performances.
Architecture hybride proposée
Les systèmes ML standards comportent deux phases : une phase d’apprentissage et une phase d’inférence. La première phase entraîne le modèle à partir d’ensembles de données, et la phase d’inférence, également appelée phase de prévision, utilise le modèle obtenu durant la phase d’apprentissage et de nouvelles données d’entrée pour effectuer des prévisions. Prenons par exemple des dizaines de milliers d’images de chiffres manuscrits, chacune portant une étiquette identifiant le chiffre de l’image : d’abord, nous utilisons ces images et étiquettes pour entraîner un modèle capable de prédire le chiffre exact présent sur une image de chiffre manuscrit. Ce processus est l’apprentissage du modèle. Une fois le modèle obtenu, nous pouvons l’utiliser pour prédire le chiffre présent sur une nouvelle image de chiffre manuscrit. C’est la prédiction ou l’inférence. En un mot, l’apprentissage consiste à appliquer une formule et l’inférence consiste à entrer un nombre dans une formule pour obtenir un résultat.
Comme la phase d’apprentissage doit construire le modèle à partir de données volumineuses, elle consomme beaucoup plus de puissance de calcul. De plus, les paramètres d’apprentissage sont souvent ajustés. La programmation GPU offre plus de flexibilité que la programmation FPGA et, une fois le modèle désiré obtenu, la mission du module d’apprentissage est terminée. Une capacité de calcul souple et de haute densité est essentielle dans la phase d’apprentissage, c’est pourquoi nous avons décidé d’utiliser un GPU pour implanter la phase de l’apprentissage.
En revanche, la phase d’inférence est beaucoup plus simple. Alors que la phase d’apprentissage comprend de nombreux cycles de calculs propagés entre les différentes couches cachées, et ce dans les deux sens, la phase d’inférence nécessite un cycle unique de calcul se propageant uniquement dans un sens. De plus, sur une période relativement longue, de nombreuses prédictions seront effectuées à l’aide du modèle. Toute augmentation de la latence ou de la consommation de puissance peut finir par totaliser une grande quantité d’énergie globale. Ainsi, pendant la phase d’inférence, une latence et une consommation de puissance faibles sont plus souhaitables que la flexibilité de calcul et la capacité de calcul à haute densité. Par conséquent, nous avons choisi un FPGA pour exécuter le module d’inférence.
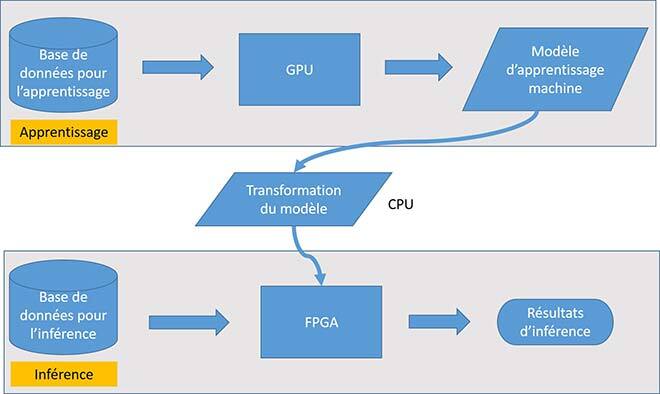
Figure 3 Architecture de systèmes.
La figure 3 présente l’architecture globale de notre système de ML, qui contient deux modules principaux, à savoir le module d’apprentissage, assuré par le GPU et le module d’inférence, réalisé par le FPGA.

Figure 4 Shéma et photo réelle.
La figure 4 montre un schéma et une image réelle du ML que nous proposons.
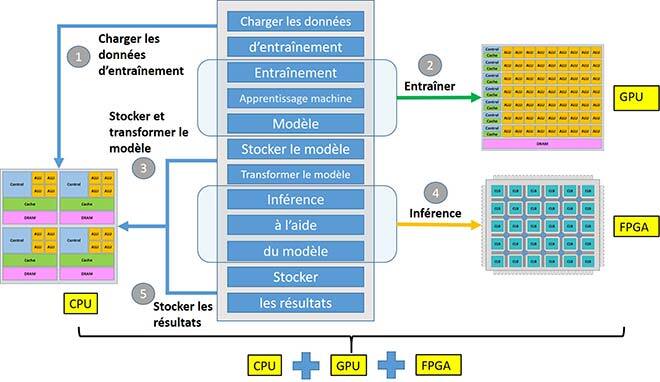
Figure 5 Diagramme du système d’apprentissage machine hybride.
La figure 5 montre le diagramme de fonctionnement de notre système hybride d’apprentissage machine. D’abord, la CPU charge les données d’entraînement à partir de la mémoire puis les achemine au GPU, lui donnant le signal de démarrer l’apprentissage. Après l’entraînement du GPU, la CPU extrait le modèle du GPU, l’enregistre et le transforme pour l’adapter à l’architecture de l’inférence. Ensuite, la CPU achemine le modèle, les données et les signaux au FPGA pour commencer l’inférence. Après la phase d’inférence, la CPU récupère les résultats et les enregistre ou les utilise pour des tâches futures.
Vitesse des phases d’apprentissage et d’inférence
Pour valider notre méthodologie, nous avons réalisé deux expériences : une portant sur la phase d’apprentissage et l’autre, l’inférence. Au cours de ces deux expériences, nous avons utilisé une base de données de chiffres manuscrits, soit un ensemble de 60 000 échantillons pour l’apprentissage et un autre de 10 000 pour tester le système. Le modèle de processeur utilisé est le Xeon(R) CPU E5-1620 v4 à 3,50 GHz d’Intel. Le modèle du GPU est le NVIDIA TITAN Xp et le modèle FPGA, Intel Arria 10 GX.
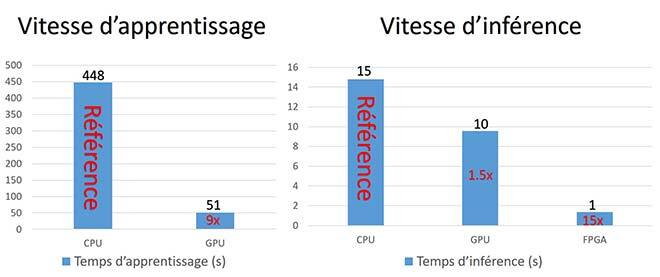
Figure 6 Vitesses de formation et d’inférence.
La figure 6 montre les résultats expérimentaux. La même tâche d’apprentissage effectuée au moyen de la CPU et du GPU permet d’obtenir une précision similaire, mais à vitesse différente. La vitesse d’apprentissage par GPU était environ 9 fois plus rapide que celle par CPU. De la même façon, la même tâche d’inférence effectuée par CPU, GPU et FPGA s’effectue à vitesse très différente pour une précision similaire. La vitesse d’interférence par FPGA était environ 15 fois supérieure à celle par CPU tandis que celle par GPU lui était d’environ 1,5 fois supérieure.
Ces résultats montrent l’énorme potentiel de notre approche de conception hybride ML. Ils démontrent également des capacités de calcul haute performance lorsque l’apprentissage est effectué par GPU et la partie inférence, par FPGA.
Conclusion
Nous avons d’abord analysé le processus d’apprentissage machine standard et les trois principales architectures de processeurs matériels, puis nous avons expliqué pourquoi la puissance de calcul haute densité provoquait un goulot d’étranglement pour le ML. Pour résoudre ce problème, nous avons proposé une méthodologie basée sur la conception d’un système ML hybride où le GPU effectue l’étape d’apprentissage et le FPGA infère les résultats. De plus, nous avons expliqué pourquoi il s’agit de la meilleure combinaison possible. Enfin, nous avons réalisé deux expériences pour vérifier notre hypothèse.
Information supplémentaire
Pour plus d’information sur cette recherche, consulter l’article de conférence suivant : Liu, Xu ; Ounifi, Hibat-Allaha ; Gherbi, Abdelouahed ; Lemieux, Yves ; Li, Wubin; Cheriet, Mohamed. 2019. “A Hybrid GPU-FPGA based Design Methodology for Enhancing Machine Learning Applications Performance”. Journal of Ambient Intelligence and Humanized Computing: 1–15.


