
Training Object Detectors with Classification Data

Purchased from Gettyimages. Copyright.
Deep learning-based object detectors recently achieved tremendous improvement in performance on benchmark datasets. However, they are trained on datasets containing large-scale bounding box annotations. This limits their adoption to practical industrial applications, as getting annotation is costly and time consuming. It is relatively easy to collect classification data where only image-level labels are needed. In this work, we propose an efficient pseudo labelling-based learning scheme leveraging classification data with limited bounding box annotations to enhance detection performance.
Annotation Challenge in Modern Deep Object Detectors
Modern Object Detectors with Deep Learning have achieved impressive results on benchmark datasets [1,2]. However, one practical bottleneck for their wide-scale adoption to industrial applications is the availability of large-scale datasets with bounding box annotations to train these detectors. Unlike detection, there are plenty of large-scale datasets available for classification, because it is easy to collect classification labels. What if we could also make use of these large-scale classification datasets to enhance the performance of object detectors? Fig 1 illustrates a setting where a detector is fed with images including bounding box annotations and simple class labels of the object categories it contains. In our study, we addressed this research question by synthesizing pseudo-bounding box labels—called pseudo ground truth (GT)—for images with class-level labels.
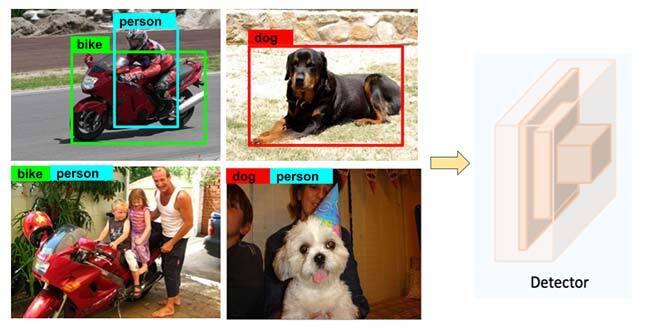
Fig 1: Training object detectors with bounding box annotations and image-level class labels.
Computing Pseudo Ground Truth Boxes
To obtain pseudo-GT boxes, we first computed candidate regions in an image where there is a high probability of locating objects. Such regions can be obtained as a pre-processing step using classical image processing techniques like selective search [3] or edge box [4]. Next, we used a sampling process to get pseudo-GT boxes corresponding to each category contained in the image. This sampling needs to have a rough clue about the location of different categories. In our method, this was ensured by a process called score propagation. Thus sampling and score propagation are the core building blocks of our method in order to leverage classification data in learning accurate detectors, as shown in fig 2.
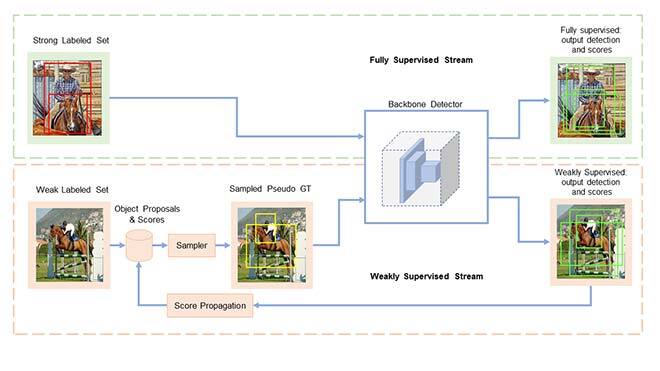
Fig 2: Proposed sampling-based learning for training object detectors with image classification data. Sampling and score propagation are the core building blocks of our method.
At each step in the training process, we fetched a batch of images from a pool of images with bounding box annotations or class-level annotations. If the image had bounding box annotations, we computed and backpropagated the standard detection losses [5] (fully supervised stream in fig 2). If the image had only class-level annotations, we sampled k—we used k=5—bounding boxes from the set of candidate regions for each category contained in the image. The sampling process was based on scores of each category for each candidate region. Specifically, for each candidate region, we kept a score vector with entries corresponding to all categories contained in that image in the memory. Before training, these score vectors were initialized to zero. At each training step, we computed the output detections and propagated the detection scores to the candidate regions. To do this, we computed the overlap between all detection boxes and candidate regions. Then the score vector of each candidate region was updated with its maximum overlapping detection box. The update magnitude was weighted by the overlap value. This process was done through the score propagation component. The sampled boxes were considered pseudo-GT boxes and we computed and backpropagated the detection losses as usual (weakly supervised stream in fig 2). This way, we could make use of classification data to learn object detectors with limited annotations. We sampled k boxes for each category, as there can be multiple objects corresponding to one class label in an image.
How Do Sampling and Score Propagation Work?


Fig 3: Heatmap of the candidate region scores from some images and their class labels (top). Evolution of the sampling process (bottom).
In order for this process to work, the sampling and score propagation must accumulate the right semantics for each category at the right locations. In the beginning, sampling is random as all candidate regions have the same score (zero). As training progresses, the detector will accumulate scores at all candidate regions iteratively. We analyzed these iteratively accumulated scores for each object category contained in the image, as shown in figure 3 top, with the score heatmap. The heatmap is showing higher importance at the locations where the corresponding object is present. Thus, even though the scores are random at the beginning, the iterative sampling and score propagation processes will accumulate accurate location information over the course of training, hence the sampler will select more accurate pseudo-GT boxes in the later stages (fig 3: right). Then the detector can leverage the vast collection of classification data with accurate pseudo-GT box annotations to enhance its detection accuracy.


Fig 4: Performance comparison with other methods (top) and detection results visualization (bottom).
In the table shown in fig 4, a comparison of the detection performance on the popular benchmark dataset pascal VOC is given. When classification data from VOC 2012 is leveraged with the limited detection data of VOC 2007, the detection AP—the metric used to compare detection performance—is improved by 5 points, making it close to the upper-bound—fully supervised with AP 80.9—where all images have bounding box annotations. Some detection examples from the enhanced detector are shown in fig 4, right. Thus, we can establish that by effectively utilizing the classification data, object detection performance can be improved.
The full paper is available in IEEE IJCNN proceedings: https://ieeexplore.ieee.org/document/9891933


