
Entraîner les détecteurs d’objets avec des données de classification

Achetée sur Gettyimages. Droits d’auteur.
Les détecteurs d’objets créés par apprentissage profond se sont grandement améliorés en ce qui a trait aux ensembles de données de référence. Cependant, ils sont entraînés sur des ensembles de données comportant des annotations de boîtes englobantes à grande échelle. Ainsi leur adoption dans les applications industrielles pratiques est limitée, car l’obtention d’annotations est laborieuse et coûteuse. Or, il est assez facile de collecter des données de classification comprenant seulement des étiquettes d’image. Ici, nous proposons une approche efficace d’apprentissage à l’aide d’un pseudo-étiquetage effectué à partir de données de classification et un nombre limité d’annotations de boîtes englobantes, en vue d’améliorer les performances de détection.
Les difficultés liées à l’annotation pour détecteurs d’objets profonds
Les détecteurs d’objets modernes créés par apprentissage profond ont atteint des performances impressionnantes sur les ensembles de données de référence [1,2]. Cependant, l’un des obstacles à leur adoption généralisée en industrie est la disponibilité d’ensembles de données avec annotations de boîtes englobantes à grande échelle pour entraîner ces détecteurs. Contrairement aux données de détection, il existe de nombreux ensembles de données à grande échelle destinés à la classification, car il est facile de collecter des étiquettes de classification. Notre objectif est d’utiliser ces ensembles de données de classification à grande échelle pour améliorer les performances des détecteurs d’objets. La figure 1 illustre un détecteur où sont saisies des images avec annotations de boîtes englobantes et d’autres avec étiquettes simples des catégories d’objets qu’elles contiennent. Dans notre étude, nous avons abordé cette question en synthétisant des étiquettes de pseudo-boîtes englobantes, appelées pseudo-vérités terrain (VT), pour des images comportant des étiquettes de classe.
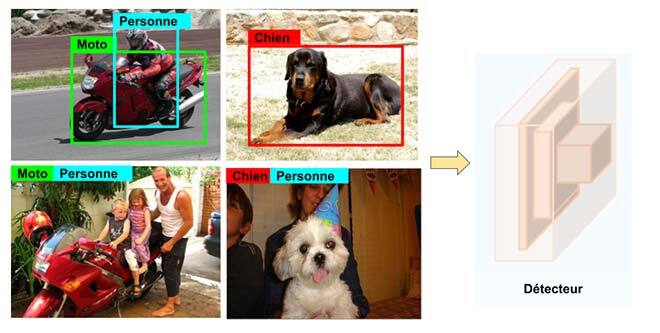
Figure 1 : Entraînement de détecteurs d’objets à l’aide d’annotations de boîtes englobantes et d’étiquettes de classe d’image.
Le calcul des boîtes pseudo-vérité terrain
Pour obtenir des boîtes pseudo-VT, nous avons d’abord calculé les régions candidates offrant une forte probabilité de contenir des objets dans une image. Ces régions peuvent être obtenues par prétraitement à l’aide de techniques classiques de traitement d’images comme la recherche sélective [3] ou la boîte de contours [4]. Ensuite, grâce à notre procédé d’échantillonnage, nous avons obtenu des boîtes pseudo-VT correspondant à chaque catégorie contenue dans l’image. Cet échantillonnage doit donner une idée approximative de l’emplacement des différentes catégories. Nous y sommes parvenus au moyen d’un procédé appelé propagation de scores. Ainsi, l’échantillonnage et la propagation de scores forment la base de notre méthode; ils nous permettent d’exploiter les données de classification pour l’apprentissage de détecteurs précis, comme le montre la figure 2.
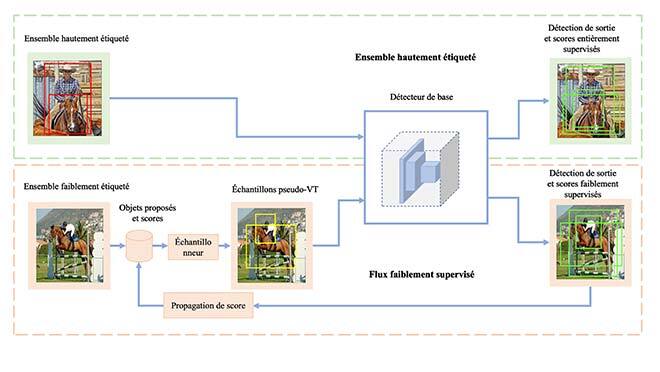
Figure 2 : Apprentissage selon le type d’échantillonnage pour entraîner les détecteurs d’objets à partir de données de classification d’images. L’échantillonnage et la propagation de scores sont le fondement de notre méthode.
À chaque étape de l’entraînement, nous prenons des images provenant d’un lot d’images avec annotations de boîtes englobantes ou de classe. Si l’image a des annotations de boîtes englobantes, nous calculons et rétropropageons les pertes de détection normales [5] (flux entièrement supervisé dans la figure 2). Si l’image ne comporte que des annotations de classe, nous échantillonnons k boîtes englobantes (ici k=5) à partir de l’ensemble des régions candidates pour chaque catégorie contenue dans l’image. L’échantillonnage se base sur les scores de chaque catégorie pour chaque région candidate. Plus précisément, pour chaque région candidate, nous avons conservé en mémoire un vecteur de score dont les entrées correspondent à toutes les catégories contenues dans cette image. Avant l’entraînement, ces vecteurs de score sont initialisés à zéro. À chaque étape de l’entraînement, nous avons calculé les détections de sortie et propagé les scores de détection aux régions candidates. Pour ce faire, nous avons calculé le chevauchement entre toutes les boîtes de détection et les régions candidates. Ensuite, nous avons actualisé le vecteur de score de chaque région candidate avec la boîte de détection où le chevauchement est maximal. L’ordre de grandeur de l’actualisation a été pondéré d’après la valeur du chevauchement. Ce procédé a été réalisé à l’aide du composant de propagation du score. Les boîtes ainsi échantillonnées ont été considérées comme des boîtes pseudo-VT et nous avons calculé et rétropropagé les pertes de détection de façon habituelle (flux faiblement supervisé, à la figure 2). De cette façon, nous avons pu utiliser les données de classification pour l’apprentissage des détecteurs d’objets avec des annotations limitées. Nous avons échantillonné k boîtes pour chaque catégorie, car il peut y avoir plusieurs objets correspondant à une étiquette de classe dans une image.
Comment fonctionnent l’échantillonnage et la propagation des scores ?


Figure 3 : Carte thermique des scores de régions candidates d’images et de leurs étiquettes de classe (en haut). Évolution de l’échantillonnage (en bas).
Pour que ce processus fonctionne, l’échantillonnage et la propagation des scores doivent respecter la sémantique pour chaque catégorie, aux endroits appropriés. Au début, l’échantillonnage est aléatoire, car toutes les régions candidates ont le même score (zéro). Au fur et à mesure de l’entraînement, le détecteur accumule des scores dans toutes les régions candidates de manière itérative. Nous avons analysé ces scores pour chaque catégorie d’objet contenue dans l’image, comme le montre la figure 3 en haut, à l’aide d’une carte thermique de scores. La carte thermique montre plus d’intensité aux endroits où l’objet correspondant est présent. Ainsi, même si les scores sont aléatoires au début, les processus itératifs d’échantillonnage et de propagation accumulent des informations précises sur l’emplacement au cours de l’entraînement, et l’échantillonneur sélectionne des boîtes pseudo-VT plus précises dans les étapes ultérieures (figure 3 à en bas). Le détecteur peut alors exploiter la vaste collection de données de classification avec des annotations précises de boîtes pseudo-VT pour améliorer son niveau de détection.
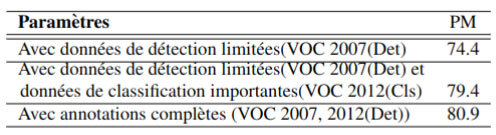

Figure 4 : Comparaison des performances avec d’autres méthodes (en haut) et visualisation des résultats de détection (en bas).
Le tableau de la figure 4 présente une comparaison des performances de détection sur le très connu ensemble de données de référence Pascal VOC. Lorsque les données de classification de VOC 2012 sont exploitées de concert avec les données de détection limitées de VOC 2007, la PM (précision moyenne) de détection (mesure utilisée pour comparer les performances de détection) s’améliore de 5 points, ce qui la rapproche de la limite supérieure (entièrement supervisé avec une PM de 80,9) où toutes les images ont des annotations de boîtes englobantes. Quelques exemples du détecteur amélioré sont montrés à la figure 4, à droite. Ainsi, nous pouvons établir que l’utilisation efficace des données de classification peut améliorer les performances de détection d’objets.
L’article complet est disponible dans les actes de l’IEEE IJCNN : https://ieeexplore.ieee.org/document/9891933


