
Dynamic Ensemble Selection Using Fuzzy Hyperboxes

Purchased from Gettyimages. Copyright.
Dynamic Ensemble Selection
In artificial intelligence, a classifier is a mathematical algorithm based on a model that assigns a class to an image, audio or text. Each classifier is a specialist that performs well under some conditions and not so well under others. Combining several specialist classifiers instead of one very complex generalist classifier can increase the performance of artificial intelligence systems while decreasing computing time. Each classifier is assigned a simpler model and can be implemented on a different computer in a distributed fashion.
When the same query is submitted to different classifiers, the answer is not necessarily the same: they may have diverging opinions. Instead of asking all the classifiers to give their opinion to combine all the answers, we can place an upstream dispatcher in charge of routing queries only to the most qualified specialists, as the case may be. The dynamic ensemble selection (DES) [1] approach uses past performances to identify these specialists. It analyzes case details and compares them to other already processed cases to find similarities. Then, using statistical models, it routes the new case to the classifiers most likely to give the correct answer.
Modeling Classifier Mistakes with Fuzzy Hyperboxes
This research paper introduces a new idea to DES: why not model classifier mistakes instead of their competencies? In a traditional classification problem, usually, experts make fewer mistakes than correct predictions. Therefore, we hypothesize that we can learn from their past mistakes instead of trying to learn only when it is a “competent” model. This concept is shown in Figure 1. On the left, we see a system trying to model the regions of competence (i.e., where the classifiers make a correct prediction) versus the regions of incompetence (on the right).
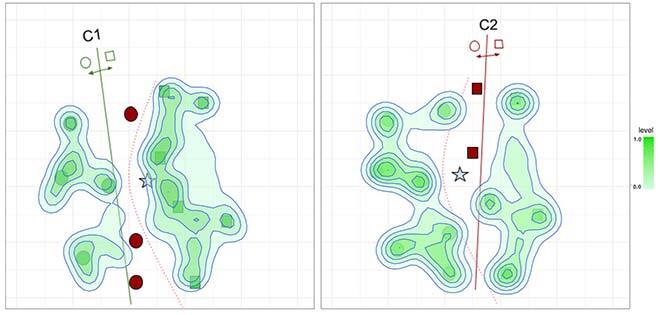
(a) Competence map of classifiers c1 and c2
(b) Incompetence map of classifiers c1 and c2
Figure 1: Competence and incompetence areas of classifiers
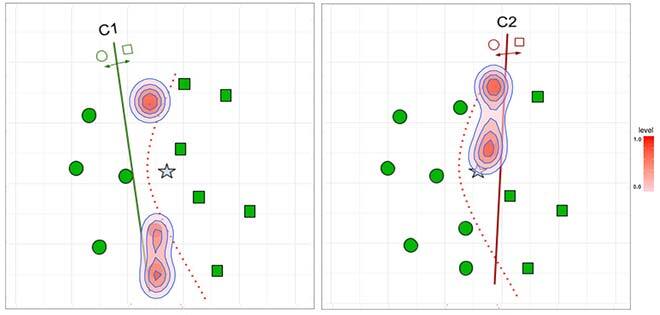
To achieve such regions (or maps), this work proposes using Fuzzy Min-Max Neural Networks (FMNN) [2,3]—models that can learn regions of the input space based on Fuzzy Hyperboxes. Hyperboxes are simple mathematical structures in a high-dimensional space that is modeled based on two points: Min (v) and Max (w) corners. The size and location of the hyperboxes are easily adjustable by changing these two corners during the training process. Each hyperbox has a fuzzy membership function that covers the surrounding area of the hyperbox so that as we move away from the hyperbox, its coverage decreases fuzzily according to the membership function. The fuzzy aspect of the hyperbox gives us valuable information outside the hyperbox, which can be used to estimate the competence of classifiers even if the query sample falls outside all Hyperboxes, allowing better modeling of uncertainty in the data.
Hence, it can be used to outline the regions of this space, where the classifiers made the correct or incorrect prediction in the training data (Figure 2). The membership function assigns each data point to the most likely hyperboxes. Figure 2 a) shows the system modeling the correct classification (positive hyperboxes) for classifiers C1 and C2, and Figure 2 b) the system modeling misclassified samples (negative hyperboxes) for the same models in a hypothetical case.
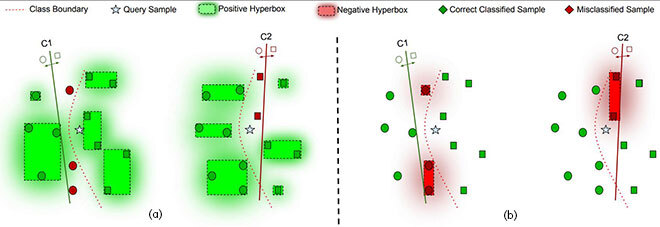
Figure 2: Solving the example of Figure 1(a) using competence information stored by Fuzzy Hyperboxes. The shaded areas represent the regions outside a hyperbox covered by the fuzzy membership function.
By modeling the positives, the idea is to look for the classifier that has positive hyperboxes near the input query (star) that is presented to the system. The fuzzy membership function helps in assigning the query to all positive hyperboxes in such a way that the one presenting the highest membership function is the one that is more likely relevant for its classification. Conversely, by modeling the negatives, we aim to select the classifiers with no negative hyperboxes close to the new input to be classified. Thus, we push away the classifiers with hyperboxes showing high degrees of membership as they are likely not good for that region. We hypothesize that modeling the negatives is beneficial for our application since it makes the problem easier, as our model just needs to focus on a few points that are usually close to the decision border (as shown in Figure 2).
FH-DES: A Promising Approach
The results obtained so far are very encouraging. Experiments conducted over 30 datasets from different fields like medical diagnosis, credit scoring, and satellite imaging demonstrate that modeling classifier mistakes helps to better select the competent classifiers. The proposed FH-DES obtained either statistically equivalent or better results than the state-of-the-art dynamic selection methods based on neighborhood estimation and competence metrics. Figure 3 shows a statistical analysis comparing the results of FH-DES versus state-of-the-art DES techniques. We can see that the proposed method obtains a higher quantity of wins than other techniques, and in most cases, this amount is deemed statistically significant based on the Sign test.
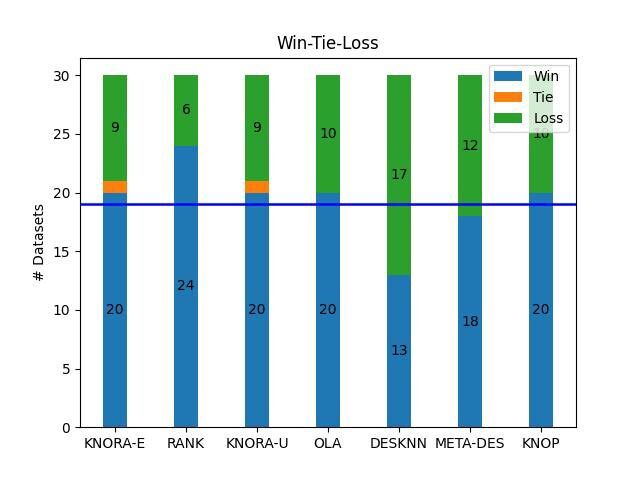
Figure 3: Comparing FH-DES against state-of-the-art DES. The blue bar represents the number of datasets in which the proposed FH-DES obtained better performances compared to the corresponding control method. The blue bar represents the cut-off point for the Sign test, indicating whether the proposed method obtains statistically superior performances with a significance level α = 0.05.
Furthermore, modeling the misclassifications is easier and necessitates much less computing and storage requirements compared to the current approaches, as shown in Figure 4. Considering two datasets, Sensor and ArData, we showed that the proposed method requires only a fraction of hyperboxes to model a dataset with over 900k instances. We generally observed that with 4k hyperboxes, we can model the whole regions, and the number of hyperboxes doesn’t increase as the dataset size increases. In contrast, DS techniques such as the traditional META-DES [4] require storing all past information in memory; thus, the system complexity increases linearly with the dataset size. This property makes our technique a good alternative for dealing with large volumes of data as it obtains good performance and a stable computational cost.
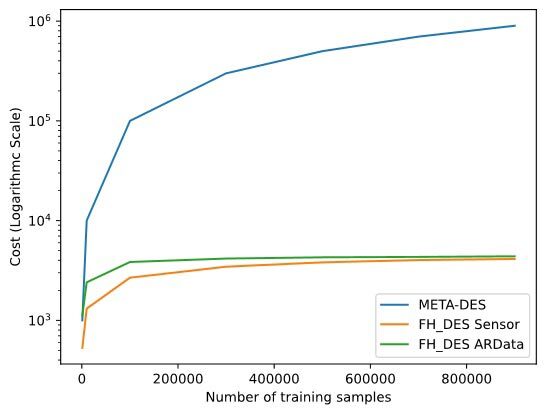
Figure 4: Computational cost versus the number of training instances. We observe that the number of hyperboxes stabilizes and we observe a plateau for two different datasets while traditional DS techniques do not.
Another advantage of considering FMNN in this context is that it can learn incrementally, with the arrival of new data being a promising solution in dealing with high volumes of data. We are currently investigating the use of FH-DES in this context to see its benefits in dealing with a continuous data stream and a system that can continuously adapt to its changes while maintaining reasonable computational costs. More details, data, and source code from our work can be found in our publication [5], and GitHub repository: https://github.com/redavtalab/FH-DES_IJCNN
Additional Information
For more information on this research, please read the following conference paper: Davtalab, R.; M.O. Cruz, R.; Sabourin, R. Dynamic Ensemble Selection Using Fuzzy Hyperboxes. The 2022 International Joint Conference on Neural Networks (IJCNN 2022).


