
Sélection d’ensemble dynamique à l’aide d’hyperboîtes floues

Achetée sur Gettyimages. Droits d’auteur.
Sélection d’ensemble dynamique
En intelligence artificielle, un classificateur est un algorithme mathématique créé à partir d’un modèle, qui attribue une classe à une image, à un fichier audio ou à un texte. Chaque classificateur est en quelque sorte un spécialiste qui fonctionne bien sous certaines conditions et moins bien sous d’autres. Combiner plusieurs classificateurs spécialistes, au lieu d’un seul classificateur généraliste très complexe, permet donc d’augmenter la performance des systèmes d’intelligence artificielle tout en diminuant le temps de calcul. Chaque classificateur se voit ainsi attribuer un modèle plus simple et peut être installé sur un ordinateur différent, de manière distribuée.
Lorsqu’on soumet la même requête à différents classificateurs, la réponse obtenue n’est pas nécessairement la même : les opinions en classificateurs peuvent diverger. Au lieu de demander à tous les classificateurs de se prononcer, puis de combiner toutes les réponses, on peut placer en amont un répartiteur chargé d’acheminer les requêtes uniquement aux spécialistes les plus qualifiés, selon le cas. La sélection d’ensemble dynamique (Dynamic Ensemble Selection, DES) [1] se base sur les performances passées pour déterminer ces spécialistes. Cette approche analyse les particularités du cas à classifier et les compare à d’autres cas déjà traités afin d’y trouver des similitudes. Puis, à partir de modèles statistiques, elle achemine le nouveau cas aux classificateurs les plus susceptibles de donner la réponse correcte.
Modéliser les erreurs de classificateurs par hyperboîtes floues
Cet article de recherche présente une nouvelle approche en DES : modéliser les réponses erronées des classificateurs plutôt que les réponses correctes. Dans un problème de classification classique, les experts font généralement moins d’erreurs que de prédictions correctes. Par conséquent, nous émettons l’hypothèse que l’on peut apprendre de leurs erreurs passées au lieu d’essayer d’apprendre uniquement d’un modèle basé sur les compétences. Ce concept est présenté à la figure 1. À gauche, un système tente de modéliser les régions de compétence (où les classificateurs font une prédiction correcte) tandis qu’à droite, il modélise les régions d’incompétence.
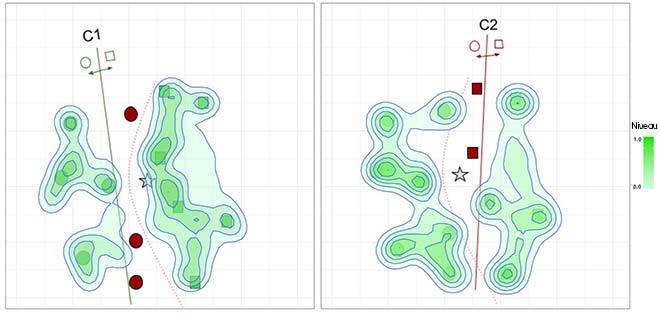
(a) Carte de compétence des classificateurs c1 et c2
(b) Carte d’incompétence des classificateurs c1 et c2
Figure 1 : Zones de compétence et d’incompétence des classificateurs
Pour obtenir ces régions (ou cartes), nous proposons ici d’utiliser les réseaux neuronaux flous Min-Max (Fuzzy Min-Max Neural Network, FMNN) [2,3], soit des modèles qui peuvent apprendre les régions du domaine d’entrée au moyen d’hyperboîtes floues. Les hyperboîtes sont des structures mathématiques simples d’un espace hautement dimensionné modélisé en deux points : les coins Min (v) et Max (h). On peut facilement ajuster la taille et l’emplacement des hyperboîtes en modifiant ces deux coins pendant l’entraînement. Chaque hyperboîte a une fonction d’appartenance floue qui couvre la zone entourant l’hyperboîte, de sorte qu’en s’éloignant de l’hyperboîte, la couverture diminue de manière floue selon la fonction d’appartenance. L’aspect flou de l’hyperboîte nous donne des informations précieuses hors de l’hyperboîte, qui permettent d’estimer la compétence des classificateurs même si l’échantillon de requête tombe dans une zone couverte par aucune des hyperboîtes, ce qui entraîne une meilleure modélisation de l’incertitude dans les données.
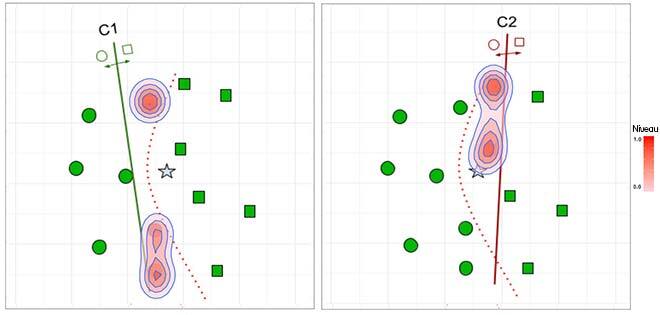
Par conséquent, cette approche peut servir à délimiter les régions dans cet espace, où les classificateurs ont fait une prédiction correcte ou incorrecte dans les données d’entraînement (figure 2). La fonction d’appartenance attribue chaque point représentant une donnée à l’hyperboîte la plus probable. La figure 2 a) montre le système modélisant la classification correcte (hyperboîtes positives) pour les classificateurs C1 et C2, et la figure 2 b) montre le système modélisant les échantillons mal classés (hyperboîtes négatives) pour les mêmes modèles dans un cas hypothétique.
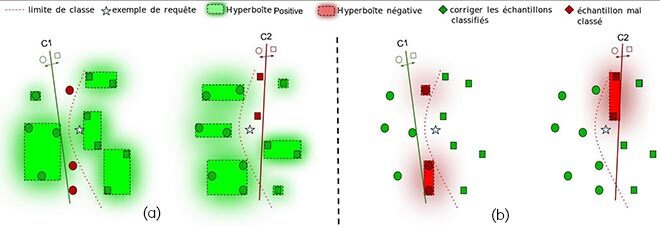
Figure 2 : Résolution de la figure 1(a) à l’aide des informations de compétence stockées par les hyperboîtes floues. Les zones ombragées représentent les régions situées en dehors d’une hyperboîte couverte par la fonction d’appartenance floue.
En modélisant les positifs, on recherche le classificateur ayant des hyperboîtes positives près de la requête d’entrée (étoile) qui est présentée au système. La fonction d’appartenance floue permet d’attribuer la requête à toutes les hyperboîtes positives de telle sorte que celle qui présente la fonction d’appartenance la plus élevée est celle qui est la plus susceptible d’être pertinente dans cette classification. Inversement, en modélisant les négatifs, on cherche à sélectionner les classificateurs qui n’ont pas d’hyperboîtes négatives à proximité de la nouvelle entrée à classer. Ainsi, nous écartons les classificateurs ayant des hyperboîtes à fort degré d’appartenance, car ils ne conviennent probablement pas dans cette région. Nous supposons que la modélisation des négatifs facilite notre application, car elle rend le problème plus facile à résoudre, le modèle n’ayant qu’à se concentrer sur quelques points qui sont généralement proches de la zone de décision (comme le montre la figure 2).
La FH-DES : une approche prometteuse
Nos résultats jusqu’à maintenant sont très encourageants. Les expériences menées sur 30 ensembles de données provenant de différents domaines (diagnostic médical, évaluation de crédit, imagerie par satellite) démontrent que la modélisation des erreurs des classificateurs permet de mieux sélectionner les classificateurs compétents. La FH-DES (Dynamic Ensemble Selection using Fuzzy Hyperboxes) proposée a obtenu des résultats statistiquement équivalents ou supérieurs aux méthodes de sélection dynamique avancées en se basant sur l’estimation du voisinage et les mesures de compétence. La figure 3 montre une analyse statistique comparant les résultats de FH-DES par rapport aux techniques de pointe de DES. On peut voir que la méthode proposée obtient une quantité plus importante de victoires que les autres techniques et, dans la plupart des cas, cette quantité est jugée statistiquement significative d’après le test Sign.
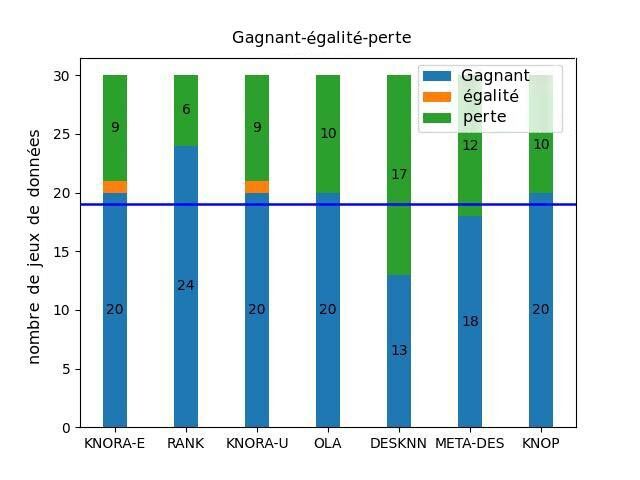
Figure 3 : Comparaison de la FH-DES avec les DES de pointe actuelles. La barre bleue représente le nombre d’ensembles de données où la FH-DES proposée a obtenu de meilleures performances par rapport à la méthode de contrôle. La ligne bleue représente le point de coupure dans le test Sign, indiquant si la méthode proposée obtient des performances statistiquement supérieures au seuil de signification α = 0,05.
En outre, la modélisation des erreurs de classification est plus facile et nécessite beaucoup moins de calcul et de stockage que les approches avancées actuelles, comme le montre la figure 4. Compte tenu de deux ensembles de données, Sensor et ArData, nous avons démontré que la méthode proposée nécessite très peu d’hyperboîtes pour modéliser un ensemble de données comptant plus de 900 k instances.
En effet, de façon générale, nous pouvons modéliser toutes les régions avec 4 k hyperboîtes, et ce nombre n’augmente pas avec la taille de l’ensemble de données. En revanche, les techniques de DS, comme la META-DES classique [4], nécessitent le stockage de toutes les informations passées, augmentant par le fait même, de façon linéaire, la complexité du système avec la taille de l’ensemble de données. Cette propriété fait de notre technique une bonne solution pour traiter de grands volumes de données, car elle obtient de bonnes performances à un coût de calcul stable.
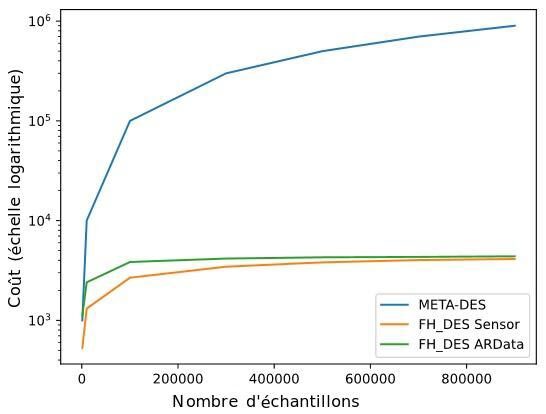
Figure 4 : Coût de calcul en fonction du nombre d’instances d’entraînement. Nous constatons que le nombre d’hyperboîtes se stabilise et observons un plateau pour deux ensembles de données différents, inexistant dans les techniques traditionnelles de DS.
Un autre avantage du FMNN dans ce contexte est qu’il peut apprendre de manière incrémentale, à mesure de l’arrivée de nouvelles données, ce qui représente une solution prometteuse dans le traitement de grands volumes de données. Nous étudions actuellement la SDE-HF dans ce contexte pour en déterminer les avantages dans le traitement d’un flux de données continu et à titre de système qui peut s’adapter continuellement à ces changements à coûts de calcul raisonnables. Vous trouverez plus de détails (données, code source) sur ce travail dans notre publication [5], et dans le répertoire GitHub : https://github.com/redavtalab/FH-DES_IJCNN
Complément d’information
Pour plus d’informations sur cette recherche, veuillez consulter les articles suivants : Davtalab, R.; M.O. Cruz, R.; Sabourin, R. Dynamic Ensemble Selection Using Fuzzy hyperboxes. The 2022 International Joint Conference on Neural Networks (IJCNN 2022).


