
Observing Information Propagation in Deep Neural Networks
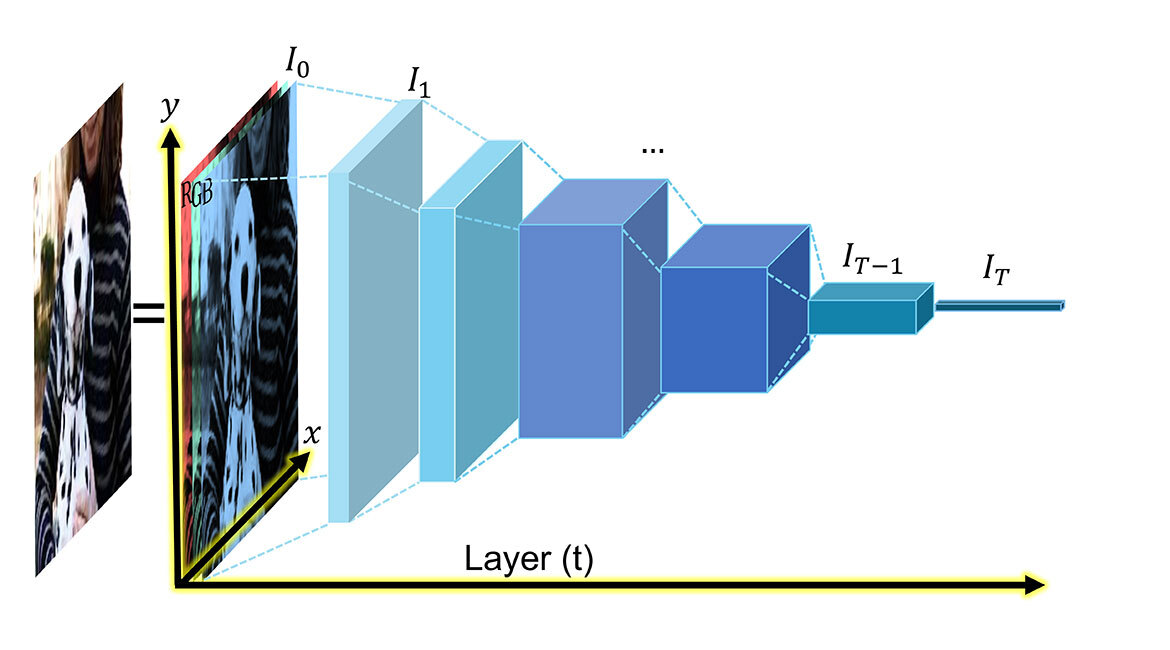
Visualization of an RGB image and a basic deep network—Convolutional Neural Network (CNN), VGG style, displaying our representation (t, x, y) of the information propagated in the network. @the authors
We are modeling and understanding how machines “perceive” information in deep neural networks (DNNs) and propose a new training recipe optimized to the intrinsic algorithm biases. Specifically, we observed that DNNs seem to identify automatically symmetric and antisymmetric information, which can be leveraged by splitting the learning function—cost function, what is being used to measure the model’s performances and guide the model during its training—into these two components. We propose to add an antisymmetric component we refer to as U(1), which we compare to a hue value in the colour wheel scheme, to the conventional (symmetric) component used in training these deep networks.
RGB Images as an Analogy to Deep Neural Networks
Modern computer vision systems mostly involve image acquisition and information processing. Little is known about the geometry of the information propagated in the Deep Neural Networks (DNNs), the de facto state-of-the-art systems for computer vision tasks such as classification or segmentation (Krizhevsky, Sutskever & Hinton, 2012). We studied the geometry of the information propagated in deep DNNs with simple analogies, generalizable observations and experiments aimed at sharing a new way of interpreting DNNs and their feature maps—how deep networks represent information.
First, we want to point out the uncommon simplification that such feature maps can be seen as a regular (RGB) image. An RGB image, as shown in header image, is a visual representation containing three channels: red, green, blue. These channels represent the response of the image to the filters of each colour informing us on the intensity spectrum. Each image pixel is characterized in five dimensions: 2D spatial position (x, y) + and 3D (R,G,B) representing the responses of primary colour filters across an electromagnetic frequency range of (400–750 THz), with (red, green, blue) wavelengths of (620–750 nm, 495–570 nm, 450–495 nm) almost an octave or doubling of frequency.
Thus, an individual RGB image is a three-dimensional DNN feature map—identical multi-channel deep network layers derived from convolution filter responses—typically implemented in graphics processing units (GPU). Human colour perception is largely based on hue, which may be viewed as angle θ in a colour wheel in the RGB colour space (Fig 1). We propose arbitrary DNN layers in a similar manner, modeling multi-channel intensity information in terms of angle θ in DNN feature space analogous to colour hue. In this way, the “colour” may be assigned to neural network pixels, for example within a convolutional neural network (CNN) used in image-based AI, where pixels in multiple layers t are associated with a set of multi-channel filter response I(x,y) at (x,y) points in an image space, as in RGB colour images. This model links activation information in deep neural networks to human colour perception and will be important in understanding the flow of information through DNNs at an intuitive level, in addition to leading to higher performance.
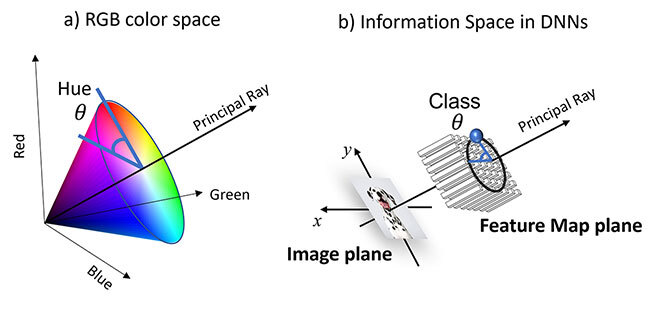
Figure 1 – Illustration of polar coordinate systems. a) The standard 3-channel red-green-blue (RGB) colour space with the hue angle θ. b) A 3-channel subspace of the ImageNet output, Deng et al. (2009), at 1000 channels, following the spatial bottleneck layer, showing a class angle θ analogous to the colour hue and defined by the class of the input image. Display of a space where a Dalmatian image is sent into a pre-trained CNN network on ImageNet converging towards a specific angle.
Adding to the One-Hot Vector Approach
Our proposition is that the image geometry, e.g. spatial position (x,y), may be as important as the DNN activation information (I), as it is in RGB images. The position of the pixel matters when you want to detect object relations to one another. Yet, most approaches disregard spatial information in the deep networks, at the feature map level, using methods that will only give their attention to average values of these feature maps. Often merging all spatial information into one global representation results in losing valuable insights. Regular deep-net training schemes then use this global representation directly in evaluating the model’s performances in their task. For example, a classification task would use the resulted final feature map, now a feature vector—a feature map with only one pixel—also known as a “one-hot” vector and compare it with our expected results to guide the model during training.
This “one-hot” vector approach demonstrated its potential numerous times. Still, we believe it is not optimized to deep neural networks due to this loss of spatial information (x,y positions). To this end, we kept this component and added a second component representing a spatial position in the form of a single value: angle θ. This angle can be compared to the hue angle in a three-dimensional colour wheel, where we are already maximizing contrast and saturation—in our case through our first “one-hot” component—and we want to further specify the colour with one angular value, as shown in Figure 1. This complementary label, which we call U(1), helps during training of the deep neural network—CNN in our case—and provides small yet consistent improvement in precision for all tasks we tested on, as shown in Table 1. In this situation, a good classification appears near the attributed class angle, like a bright, high-intensity colour pixel maximizing saturation and brightness at a specific colour. An uncertain classification—with low confidence from the model—would result in no specific angle predicted, like a grey-ish pixel.
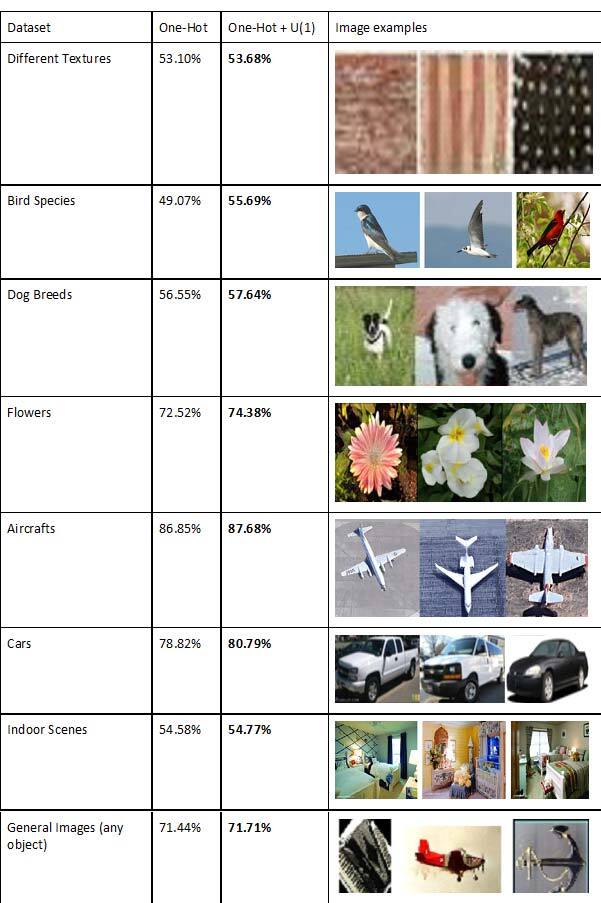
Table 1 – Precision results (/100) on various classification tasks where the goal is to identify what appears in the images. The results show the percentage of correctly identified images after training on the dataset with the one-hot “regular” approach and the one-hot component with our additional component.
These small yet consistent improvements show the potential of adding such a spatial component to the function (loss function) used for training deep networks, which we believe can be much more significant if optimized properly. We confirmed this behavior on a multitude of deep network architectures as well as many different tasks and task complexities. This work acts as a proof-of-concept introducing our U(1) theory, but more importantly introducing a new training recipe optimized to the intrinsic algorithm biases we observed. More details can be found in our publication, Bouchard et al. (2022).


