
Learning to Segment from a Single Example

Anolytics.ai. No knows usage restrictions.
When a child first sees a car, he or she instantly acquires the ability to recognize new, even different models of cars. More generally, humans possess the impressive ability to adapt rapidly in order to tackle new tasks efficiently, such as recognizing new types of objects or the sounds of a new language, from very limited past supervision. For instance, modern deep networks trained to classify cars and trucks would typically require hundreds of annotated bike images in order to acquire the ability to recognize bicycles reliably, as simple as this new task may appear. In this work, we focus on the important task of segmenting objects in images—widely used in key industrial applications—such as medical imagery or autonomous driving, where data annotation can be prohibitively expensive. We propose a simple method that allows a model to leverage its past knowledge in order to learn to segment new types of objects from as little as a single annotated example.
Data – A Curse to Segmentation
In order to blur our background, Zoom’s algorithms first need to correctly detect and segment our face from our camera frames. But how can it automate this tedious process? That’s a challenging question the computer vision community has been focusing on for several decades, with key applications ranging from medical imagery to autonomous driving. Modern Artificial Intelligence (AI) models based on Neural Networks have proven particularly effective at tackling segmentation. However there is no free lunch: they require significantly more (clean and annotated) data to be trained on. So what then? Well, in some applications, adequately annotating all objects in a single image can take up to several hours for a human annotator. While huge tech companies may afford such efforts, most non-specialized industries cannot, and wouldn’t even have the proper expertise to train models from scratch if they could. This is where few-shot learning comes into action.

Figure 1: Our method in action. The model has never seen a bike before. We fed it a single example of what a bike looks like (left image) and asked it to segment the bike in another image (second image from left). Our formulated baseline yielded adequate results, yet our refined method was able to capture the bike almost perfectly.
Few-Shot Learning
As previously mentioned, as models get bigger and computational requirements increase, very few actors can afford to create very large datasets and publicly release trained models. Downstream users—academic researchers or industrial partners—need only to “specialize” the models to their own tasks. Few-shot learning—one of the trendiest topics in AI—aims at using a model’s accumulated knowledge in order to boost its adaptive speed to new/unseen tasks. Such transfer of knowledge becomes increasingly challenging as the “source” data—data the model was originally trained on—becomes increasingly different from the “target” data—new/sparse data we want to adapt the model to. This also holds true for humans: learning Spanish as a French speaker is significantly easier than learning German, as the number of shared roots/structures is much higher. Current evaluation of few-shot methods typically overlooks this type of question, with a clear trend towards increasingly complex methods.
A Simple Idea
As opposed to the current trend, we aim for simplicity. Instead of trying to design a specific neural architecture to tackle the problem—as is done by virtually all competing methods—we train a standard model with standard supervision. The whole idea revolves around regarding this trained model as a feature extractor rather than an actual segmentation model. Using the features produced by the model, we can build a simple binary classifier (0=background, 1=foreground) that operates on each pixel. This overlooked baseline already provides adequate results (cf. third image from the left on Fig. 1). Using tools from information theory, we sharply refine this baseline to obtain our final method (right image on Fig. 1). Besides its conceptual simplicity, a significant advantage of our method is its ability to work on top of virtually any trained model. Additionally, we show it exhibits significantly better performances than existing methods (cf. Table 1), and can cope with even more challenging shifts in data distribution.
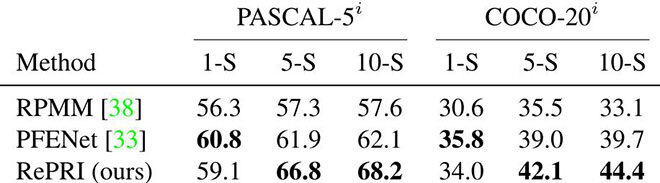
Table 1: Our method (last row) compared to most competitive methods over 6 scenarios. The metric used is the mean Intersection-over-Union (higher is better). In 4/6 scenarios, our method performs significantly better.
Conclusion
Few-shot learning tries to alleviate the growing issue of annotation costs by specializing a pre-trained model in a new task with as few as a single annotated sample. In this work, we revisited standard ideas from information theory to produce a simple and practical method for few-shot segmentation. We hope future works follow along this idea of simplicity, and focus on developing methods with actual potential for real-world applications.
Additional Information
Please find the full article under the following reference:
[1] Boudiaf, Malik, et al. “Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need?” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
A few words about the conference: The Conference on Computer Vision and Pattern Recognition (CVPR) is an annual conference on computer vision and pattern recognition, regarded as one of the most important conferences in the field, and ranks among the 5 most impactful venues, all fields included, according to Google Scholar metrics https://scholar.google.com/citations?view_op=metrics_intro&hl=fr.


