
Un drone commandé par l’IA pour fournir des services sans fil

Achetée sur Istockphoto.com. Droits d’auteur.
Nous étudions ici la possibilité de fournir des services sans fil par véhicule aérien sans pilote à voilure tournante, aussi appelé UAV (unmanned aerial vehicle) ou drone, servant de base aérienne (BA) pour communiquer avec de multiples terminaux au sol (TS) dans une zone à forte demande. Notre objectif est d’optimiser la commande du drone afin d’en maximiser l’efficacité énergétique, tenant compte à la fois de l’énergie aérodynamique et de l’énergie nécessaire à la communication, tout en respectant les exigences de communication des TS et en assurant une liaison de retour entre drone et BA terrestre. La mobilité des drones et des TS entraîne des conditions de canal variables dans le temps, ce qui rend l’environnement dynamique. Nous avons formulé un problème d’optimisation non convexe pour manœuvrer le drone en tenant compte des canaux d’évanouissement de Rice, qui dépendant de l’angle entre drone et TS et entre drone et BA terrestre. Les approches d’optimisation classiques ne peuvent pas gérer les environnements dynamiques ni la grande complexité du problème en temps réel. Nous proposons d’utiliser une approche fondée sur l’apprentissage profond par renforcement, à savoir la TRPO (Trust Region Policy Optimization) pour résoudre le problème non convexe de commande du drone en continu. Cette approche tient compte de l’environnement en temps réel et des conditions variables dans le temps du canal drone-sol, de l’énergie disponible à bord du drone et des exigences de communication des TS.
Fournir des services de communication à l’aide de drones
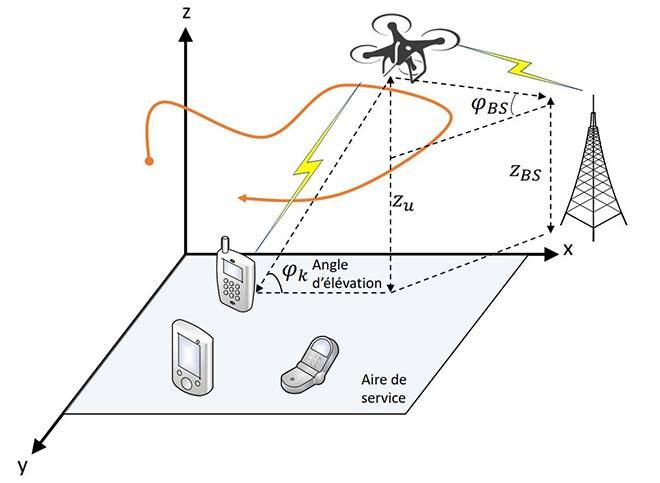
Figure 1 : Schéma de notre modèle.
La technologie des drones UAV de communication est en plein essor afin de permettre aux systèmes 5G de fournir une connectivité fiable et répandue aux utilisateurs mobiles. En effet, les drones équipés d’émetteurs-récepteurs sans fil embarqués peuvent survoler une zone cible et fournir des services de communication là où le déploiement de BA terrestres est difficile ou quand les infrastructures de communication se trouvent en zone sinistrée. Grâce à leur grande maniabilité, les drones peuvent ajuster leur position aérienne en fonction de la localisation en temps réel des TS, ce qui permet d’économiser de l’énergie et d’améliorer les performances de communication. De plus, en survolant les TS à une altitude donnée, les communications par drone peuvent donner un canal de meilleure qualité puisque la communication avec les TS est principalement dépendante des liaisons LoS (Line of Sight). Par exemple, un drone volant à 120 m dans un environnement rural peut fournir des liaisons air-sol avec une probabilité de LoS supérieure à 95 %. Ainsi, la communication sans fil par drone est prometteuse et rentable pour les systèmes 5G, car elle favorise les opérations à la demande et facilite le déploiement rapide et flexible d’infrastructures de communication.
Parallèlement à ces avantages, les systèmes de communication sans fil par drone présentent de nombreux défis. En particulier, l’exploitation d’un drone dépend essentiellement de l’énergie à son bord, limitée selon l’appareil et la taille de la batterie. Il est donc nécessaire de concevoir un mécanisme permettant d’utiliser cette énergie limitée de façon à améliorer les performances de communication tout en prolongeant l’endurance des drones. En effet, par rapport aux BA terrestres classiques, les drones consomment davantage d’énergie de propulsion pour rester en suspension et assurer leurs déplacements. De plus, la mobilité des drones et des TS entraîne des conditions de canal variables dans le temps, ce qui rend l’environnement dynamique. Par conséquent, concevoir un système de communication sans fil écoénergétique pour drones est plus difficile et diffère considérablement des systèmes de communication terrestres classiques.
Pour surmonter les défis de l’énergie limitée à bord, nous tirons parti des performances supérieures de l’apprentissage profond par renforcement, le DRL (deep reinforcement learning), pour gérer un environnement variant dans le temps, comprenant un espace-état complexe. Le DRL utilise de puissants réseaux neuronaux profonds (DNN) pour produire une loi de commande stationnaire optimale sans nécessiter une connaissance poussée des statistiques de l’environnement dynamique.
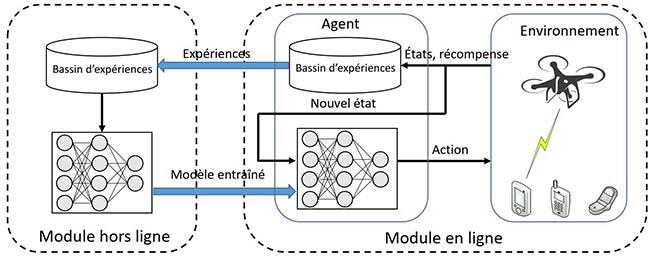
Figure 2 : Architecture à deux modules proposée, basée sur la TRPO pour application pratique.
L’apprentissage profond par renforcement
La commande des drones peut être formulée selon le processus de décision de Markov ou MDP (Markov decision process) :
- États du système : l’état du réseau dans l’intervalle de temps t peut se caractériser par le gain de puissance du canal entre drone et TS, l’énergie disponible du drone et les besoins en données restants des TS au temps t.
- Actions : l’action du drone au temps t correspond aux vitesses horizontale et verticale.
- Récompense : en apprentissage par renforcement, la fonction récompense doit être liée à la fonction objectif. Par conséquent, nous avons conçu une récompense combinée, liée au débit de données atteint par les TS et la consommation d’énergie du drone.
Les résultats de notre simulation sont illustrés à la figure 3.
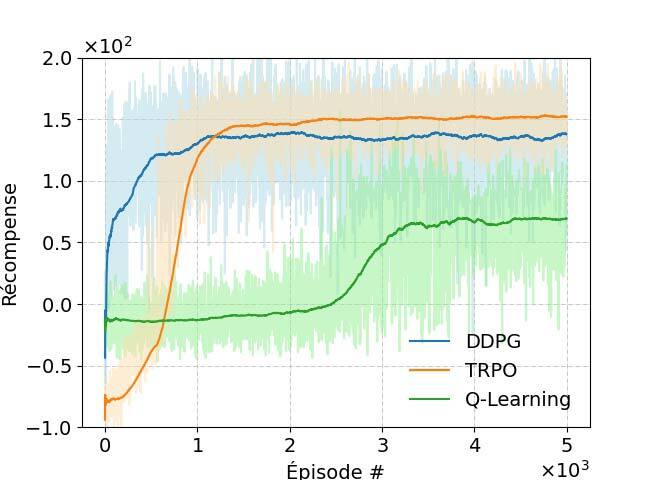
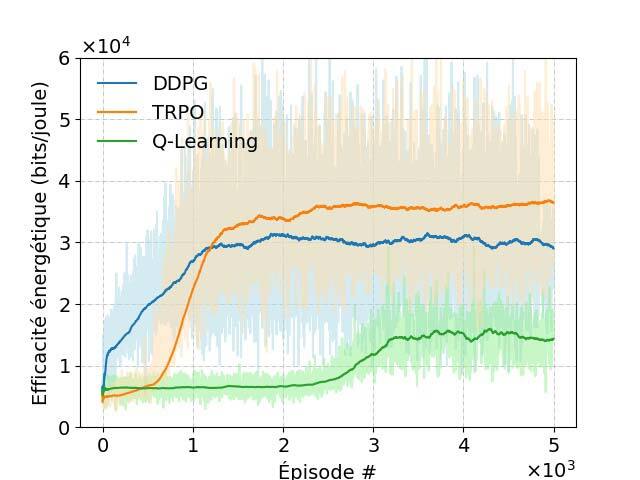
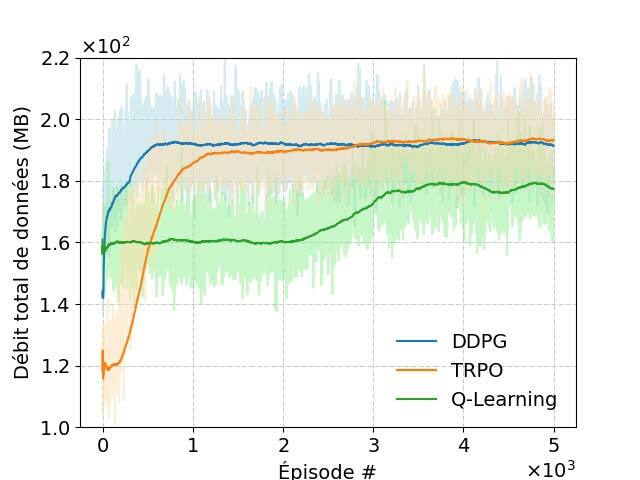
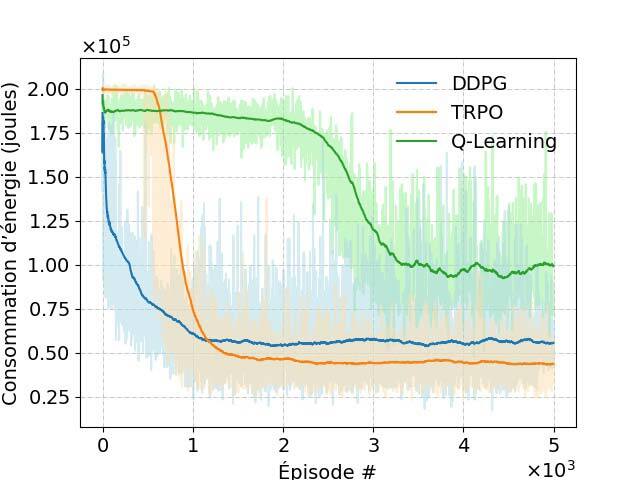
(a) Récompense moyenne (b) Consommation d’énergie (c) Débit de données total réalisable (d) Efficacité énergétique
Figure 3 : Performance du schéma DRL proposé.
Conclusion
Nous proposons ici une approche basée sur l’apprentissage profond par renforcement pour commander des drones tout en minimisant la consommation d’énergie. Les résultats numériques révèlent que l’algorithme TRPO peut améliorer les performances par rapport à l’algorithme DDPG (deep deterministic policy gradient) dans un environnement hautement dynamique, comme décrit ici. De plus, les algorithmes TRPO et DDPG démontrent une meilleure efficacité énergétique que l’algorithme de base Q-Learning et l’algorithme heuristique.
Remerciements
Les auteurs remercient Mitacs, Ciena et ENCQOR pour le financement de cette recherche dans le cadre de la bourse IT13947.
Pour plus de détails, voir l’article complet ; référence ci-dessous [1].


