
SLK : un algorithme de partitionnement performant

Achetée sur Istock.com. Droits d’auteur
L’apprentissage machine sans supervision au moyen d’exemples s’appelle l’apprentissage non supervisé. L’analyse de partitionnement (cluster) est une méthode d’apprentissage non supervisée très courante qui vise à grouper des instances similaires à partir d’un ensemble de donnés non étiquetées. Dans les scénarios à grande échelle, les solutions de partitionnement et l’évolutivité peuvent s’avérer problématiques. Nous proposons ici une méthode efficace nommée K-modes laplacien évolutif (Scalable Laplacian K-modes, SLK) qui combine deux objectifs de partitionnement basés sur centroïdes et par paires dans une même formulation pour optimiser efficacement et rapidement l’algorithme distribué en offrant une meilleure performance que la plupart des méthodes existantes.
Organiser une énorme quantité de données
Les progrès des technologies d’acquisition de données par Internet, médias numériques, réseaux sociaux, vidéosurveillance et les secteurs commerciaux en croissance ont produit des quantités massives de données de grandes dimensions. Afin de créer un modèle ingénieux relativement aux applications qui s’y rapportent, il faut pouvoir manipuler ces énormes volumes de données. Il est donc nécessaire de faire l’analyse automatique des données. La littérature dénombre une grande quantité d’algorithmes de partitionnement, outils permettant d’analyser des données par l’extraction de modèles similaires de distribution des données, de manière non supervisée. Ces techniques ont servi à un large éventail d’applications en analyse de données commerciales, de marché, de réseaux sociaux et beaucoup d’autres liées à l’IA. Cependant, organiser une grande quantité de données hautement dimensionnelles en groupes significatifs est très difficile en raison de problèmes d’évolutivité et d’efficacité. C’est le cas par exemple des sites de partage de photos populaires comme Facebook ou Instagram, où il faut gérer le téléchargement de millions de photos par jour.
Images classées par caractéristiques similaires
De nombreux algorithmes de partitionnement sont proposés dans la littérature. Toutefois, un algorithme de partitionnement particulier convenant à une application précise ne réussit pas nécessairement dans des applications connexes. Nous proposons le SLK (Scalable Laplacian K-modes) : une méthode de partitionnement qui combine deux modèles bien connus et fournit une manière intelligente d’optimisation pour obtenir un algorithme distribué rapide et offrant une meilleure performance que la plupart des méthodes existantes. Ce travail de recherche a été qualifié d’article vedette par NeurIPS (Neural Information Processing Systems), considéré sans contredit comme la plus grande conférence d’IA et d’apprentissage machine.
Partionnement par K-modes laplacien évolutif (SLK)
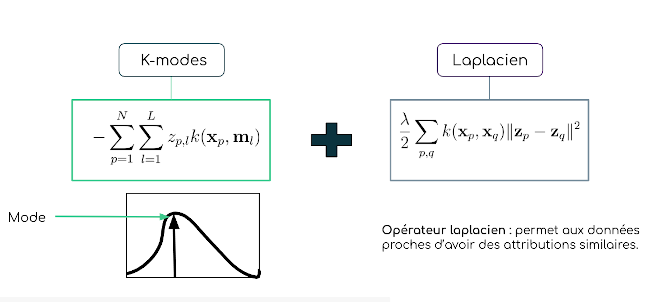
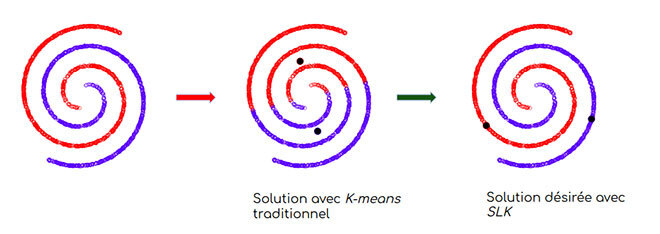
Comme nous l’avons dit, le SLK combine deux modèles : K-modes et le bien connu laplacien. Les K-modes repèrent le mode de chaque grappe, comme dans la très populaire méthode de l’écart moyen. Le terme « mode » désigne en gros l’échantillon le plus représentatif du sommet d’une distribution. Le terme « laplacien » apporte de la cohérence dans les grappes en imposant les mêmes attributions pour les échantillons de données proches et aide ainsi à trouver des grappes structurées multiples comme les spirales illustrées ci-dessous.
Bien que prometteur, ce modèle pose un problème d’optimisation très complexe en raison de contraintes discrètes et laplaciennes. Nous proposons une relaxation concave-convexe de la formulation et une méthode d’optimisation itérative qui résout la parallèle du problème de partitionnement à chaque itération. Cette solution fournit également le mode représentatif de chaque grappe comme sous-produit en complexité de temps linéaire, que nous appelons SLK-BO. Cette approche rend l’algorithme plus rapide que la variante SLK-MS qui repère le mode avec un algorithme itératif.
Nous avons effectué des expériences élaborées sur divers ensembles de données contenant pour la plupart des images ou des données numériques. Nous utilisons le NMI (Normalized Mutual Information) et l’ACC (clustering ACCuracy) comme mesures de performance. Plus les valeurs sont élevées, meilleures sont les performances. Nous évaluons également le temps en secondes nécessaire à l’organisation des données. Plus le temps est bas, meilleure est la performance.
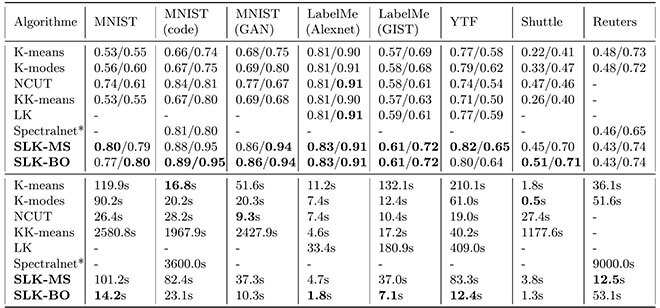
Tableau : NMI/ACC obtenus, partie supérieure; temps écoulé moyen en secondes, partie inférieure.
D’après le tableau, on peut observer que la méthode SLK-MS/SLK-BO est supérieure en précision et en rapidité. Par exemple, dans l’ensemble de données MNIST, colonne (code), 95 % des images ont été organisées correctement, de façon automatique, en fonction de leur similarité, et sans supervision. Également, pour ce qui est de la synchronisation, SLK est beaucoup plus rapide que les autres méthodes, en particulier pour les ensembles de données de grandes dimensions comme LabelMe (GIST) et YTF, et évolutif pour ce qui est des grands ensembles de données Reuters.
Informations supplémentaires
Les détails techniques sur le groupement SLK (SLK clustering) sont décrits dans l’article de Neurips : https://papers.nips.cc/paper/8208-scalable-laplacian-k-modes.pdf.
Le langage Python est décrit à : https://github.com/imtiazziko/SLK


