
Sélection de clients pour l’apprentissage fédéré dans l’IdO

Achetée sur Istockphoto.com. Droits d’auteur.
Solution de rechange aux modèles centralisés, l’apprentissage fédéré (Federated Learning, FL) nous permettrait de franchir une nouvelle étape dans la protection des données. En FL, les données brutes sont conservées à même les dispositifs, tandis que les modèles partagés sont traités localement, puis agrégés de façon globale en plusieurs cycles. Les clients participants sont sélectionnés de façon aléatoire ou quasi aléatoire. Cependant, l’hétérogénéité des données des clients IdO et leurs ressources limitées peuvent nuire à l’apprentissage et affecter la précision du modèle. C’est pourquoi nous proposons FedMCCS, une approche multicritères de sélection de clients pour apprentissage fédéré. UCT, mémoire, énergie et temps sont tous pris en compte dans les ressources clients et le nombre de clients FedMCCS est maximisé pour chaque cycle. Mots clés – Apprentissage fédéré, Internet des objets, sélection multicritères, gestion des ressources.
Défis des systèmes d’apprentissage fédéré
Aujourd’hui, la multiplicité des données générées par les appareils mobiles et l’IdO rendent les applications de plus en plus intelligentes. Cependant, ces données sont stockées dans une entité centrale, entraînant un enjeu majeur quant à la protection de la vie privée.
Pour résoudre ce problème, Google a adopté le terme apprentissage fédéré (FL) pour aborder la confidentialité des données. Dans ce type d’apprentissage, plutôt que d’envoyer des données dans le nuage, des modèles d’apprentissage machine (AM) sont formés localement à même les dispositifs. Les modèles générés sont ensuite envoyés au serveur pour agrégation, produisant un modèle global amélioré.
Toutefois, différents ensembles de clients sont sélectionnés de façon aléatoire [1] ou quasi aléatoire [2] d’un cycle à l’autre. Lorsque des clients IdO à ressources limitées sont sélectionnés, leur temps de traitement est non seulement plus long, mais l’apprentissage peut échouer, affectant ainsi la précision du modèle.
Protocole amélioré d’apprentissage fédéré
Pour répondre aux défis susmentionnés, une approche de sélection de clients se basant sur plusieurs critères a été proposée pour notre protocole FL, tenant compte de la disponibilité des ressources de chacun. La figure 1 illustre l’architecture à haut niveau du cadre proposé. D’abord, une communication entre les deux entités (dispositifs IdO et serveur) est lancée pour connaître les ressources du client. Selon la réponse obtenue, un algorithme de régression linéaire est utilisé afin de déterminer la capacité en UCT, en mémoire et en énergie du client pour effectuer la tâche d’apprentissage. Le temps estimé pour le téléchargement, la mise à jour du modèle et le téléversement est également calculé et comparé à un seuil défini par le serveur.
Grâce à ces mesures, l’approche proposée permet de maximiser le nombre de clients sélectionnés, d’agréger plus de mises à jour par cycle et de minimiser le nombre de cycles de communication.
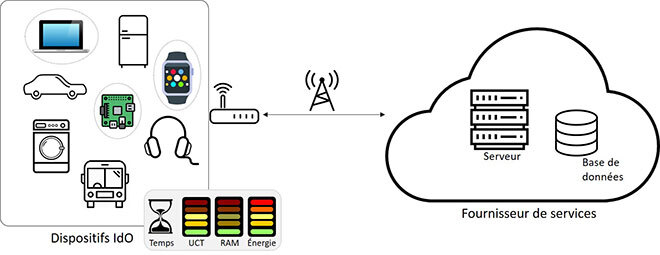
Figure 1. Architecture à haut niveau du cadre proposé.
Validation de la méthode proposée
Une étude de cas nous a permis d’examiner la détection d’intrusions sur le réseau, où de bons modèles peuvent faire la distinction entre les connexions normales/adéquates et les intrusions/attaques. Pour cette tâche, nous avons utilisé l’ensemble de données NSL-KDD [3] et considéré 100 clients, à raison d’un maximum de 10 clients sélectionnés par cycle.
Nous avons comparé notre approche avec les deux références suivantes :
- VanillaFL : Approche FL originale [1] où 10 clients sont sélectionnés au hasard par le serveur pour participer aux cycles FL.
- FedCS : FL avec sélection de clients [2], où 10 clients sont d’abord sélectionnés au hasard par le serveur pour partager leurs ressources. FedCS, où seul le temps nécessaire pour obtenir les mises à jour des clients est représenté, a été utilisé pour sélectionner les clients.
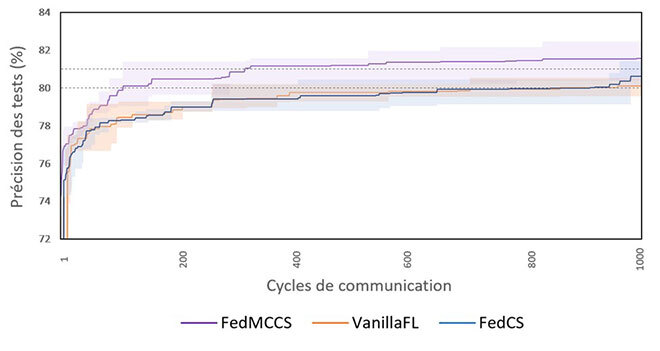
Figure 2. Précision des tests c. cycles de communication
La figure 2 montre le nombre de cycles de communication requis pour atteindre une précision de 80 %. Les zones ombrées représentent l’écart type de cinq exécutions. Notez que notre approche FedMCCS est plus performante que les deux autres en ce qui a trait aux cycles de communication. Pour atteindre une précision de 80 %, FedMCCS nécessite 108 cycles, alors que ce nombre augmente de 8,0 x pour VanillaFL, à raison de 861 cycles, et de 8,4 x pour FedCS, à raison de 912 cycles. Ces résultats sont probablement dus au fait que nous avions plus de clients participant aux cycles FL.
La variation des clients sélectionnés capables de terminer l’apprentissage, sans abandon, a également été étudiée. En particulier, la figure 3 montre que FedMCCS sélectionne le plus grand nombre de clients performants, puisqu’il tient compte de nombreux critères (UCT, mémoire, énergie et temps) affectant les abandons.
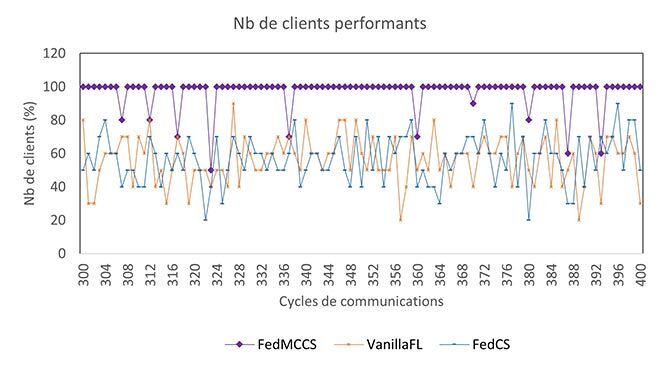
Figure 3. Variation du nombre de clients sélectionnés par cycle
D’autre part, un cycle est considéré comme rejeté lorsque moins de 70 % des clients sélectionnés n’envoient pas leurs paramètres de modèle au serveur. Nos expériences démontrent que FedMCCS ne produit que quelques cycles rejetés, par rapport aux deux autres, comme le montre la figure 4. Par conséquent, nous pouvons voir que plus nous avons de clients, plus la précision est élevée et moins il y a rejet de cycles.
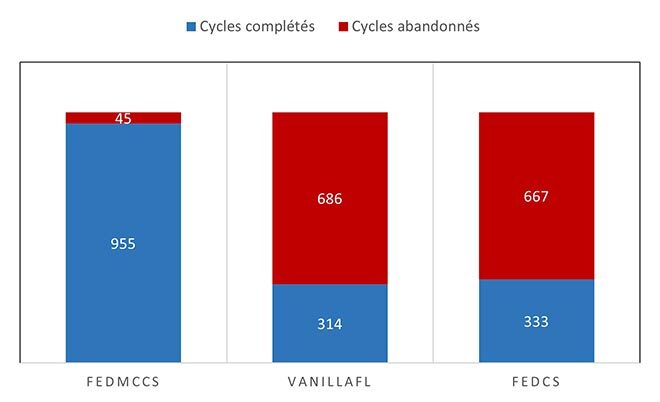
Figure 4. Cycles FL achevés c. cycles rejetés sur 1000
Conclusion
Notre proposition FedMCCS est un apprentissage fédéré amélioré prévoyant une sélection multicritères de clients, soit un schéma d’optimisation qui peut efficacement sélectionner et maximiser le nombre de clients participant à chaque cycle, tout en considérant leur hétérogénéité et leurs ressources limitées de communication et de calcul.
Des expériences réelles démontrent que FedMCCS est capable de former et de produire des modèles d’AM très performants avec moins de cycles de communication que les approches et protocoles existants.


