
Segmentation de motifs de manuscrits anciens

Achetée sur Istockphoto.com. Droits d’auteur.
Ces dernières années, la numérisation des documents, en particulier des manuscrits anciens, suscite un intérêt considérable du point de vue de l’histoire et du développement social. Comme les documents historiques sont détériorés et vieillis, les copier sur un réseau en ligne a résolu le problème de préservation et d’accès. Pour l’analyse des données de ce genre de document, l’un des défis demeure la reconnaissance des motifs importants, en raison des caractéristiques complexes des documents historiques, pour les utilisateurs qui ne disposent pas des outils appropriés. Aussi, nous proposons une méthode pratique d’apprentissage profond pour segmenter simultanément les informations essentielles dans les documents historiques. Ce mécanisme pourrait offrir aux scientifiques un moyen précis de déchiffrer les secrets des manuscrits anciens. L’approche proposée tire parti du potentiel du réseau adverse génératif pour améliorer la qualité des motifs de ces documents.
Caractéristiques critiques des documents historiques
À la différence des autres types de documents, l’analyse des manuscrits anciens est un domaine de recherche actif [1]. Chaque document historique contient divers types d’objets essentiels, comme la légende, le tableau, le dessin, le mot flottant, le paragraphe et la page. La figure 1 donne une vue claire des caractéristiques essentielles d’un document.

Figure 1: Différents objets dans un manuscrit ancien.
Descripteur de segmentation
L’idée fondamentale derrière la segmentation des images d’un document est de regrouper les pixels extraits. Les caractéristiques sont représentées par les similarités spatiales entre les différents pixels d’une région donnée. Dans ce cas, segmentation signifie le procédé de séparation d’une image numérique en plusieurs zones (ensembles de pixels) pour obtenir une représentation de l’image plus significative et plus facile à analyser.
Défis de la segmentation des documents historiques
Les techniques de segmentation ont été créées pour pallier le problème de l’extraction des éléments visuels. La plupart des approches de segmentation d’objets sont basées sur l’apprentissage supervisé et chaque objet nécessite une étiquette, ce qui augmente le temps de traitement et requiert une expertise spécialisée pour annoter les données. Ce processus d’annotation augmente la possibilité d’erreur associée à une image de document en entrée.
Une autre difficulté des méthodes d’apprentissage supervisé est le manque d’images provenant de documents historiques, ce qui empêche d’atteindre une grande précision dans la segmentation des différents objets. Bien que les approches de détection et de segmentation d’objets se basent principalement sur l’apprentissage supervisé, nous proposons de segmenter ces entités de manière non supervisée. De plus, la méthode que nous proposons peut générer un jeu de données artificielles permettant d’éliminer les problèmes liés au manque d’images de documents historiques.
Cadre proposé
Nous proposons ici un modèle à deux volets représentant chacun un objectif : la génération d’images de haute qualité et la segmentation simultanée de divers objets. Nous ajoutons également une fonction objective hybride qui permet à l’utilisateur d’appliquer les résultats (taux d’apprentissage, poids et biais) du premier volet au deuxième volet afin de réduire le temps de traitement. Le modèle proposé permet l’extraction optimale des caractéristiques.
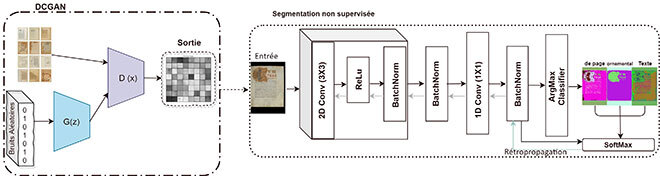
Figure 2 Architecture de l’analyse des documents historiques
Augmentation des données par la méthode des réseaux adverses génératifs (GAN)
La première étape de la méthode proposée s’effectue à partir de deux réseaux neuronaux. Le premier réseau reconstruit de fausses images qui sont en fait des versions améliorées des images de documents historiques existants. Le second réseau neuronal compare les images générées aux images réelles. En d’autres termes, le second réseau est un réseau de classification qui examine les images de documents réels à la sortie du générateur, et décide s’il s’agit d’une image réelle ou fausse. Cette manipulation se poursuit entre les fausses images jusqu’à ce que le modèle estime que les images générées sont des images réelles. Ces images reconstruites peuvent alors être considérées comme nouvelles ressources pour la tâche de segmentation.
Méthode de segmentation non supervisée
Afin de localiser avec précision la zone d’intérêt de différents objets dans un manuscrit ancien, nous avons choisi un réseau neuronal convolutif bidimensionnel. Comme le nombre d’objets dans chaque document est inconnu, les pixels les plus itérés sont regroupés sous forme de grappes, et les pixels voisins sont considérés comme un segment. Ce processus tire avantage de l’approche de regroupement k-moyennes pour générer des superpixels. Le réseau peut alors attribuer ces superpixels aux différentes caractéristiques d’une image de document.
Résultats
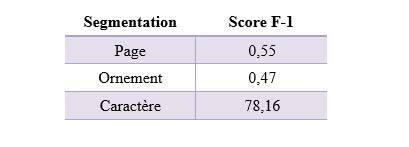
Dans la phase d’évaluation, nous avons analysé l’approche proposée à l’aide de trois jeux de données différents. Le score F-1 a servi de critère d’évaluation pour comparer les caractéristiques entre les images réelles du document et les masques générés.
La figure 3 montre certains des résultats qualitatifs. L’approche proposée a été testée pour trois ensembles de données différents et a pu segmenter des informations supplémentaires dans les manuscrits anciens.

Figure 3 Exemples de données générées et de caractéristiques segmentées.
a) Page segmentée, b) Ornement segmenté, c) Caractère segmenté.
Conclusion
Dans cet article, nous proposons une nouvelle technique de segmentation de documents, basée sur l’apprentissage profond, pour segmenter différentes caractéristiques simultanément. L’étape d’augmentation des données reconstruit des images de haute qualité tandis que la segmentation délimite différents objets. Cette approche peut également diviser les images en partitions distinctes d’objets pour accélérer les tâches de reconnaissance et obtenir de meilleures performances d’analyse.
Informations complémentaires
Pour plus d’informations sur cette recherche, lire l’article suivant :
Tamrin, M.O. and Cheriet, M., 2021, January. Simultaneous detection of regular patterns in ancient manuscripts using GAN-Based deep unsupervised segmentation. International Conference on Pattern Recognition


