
MicroMiner pour l’identification des microservices
@Imen Trabelsi
L’architecture en microservices (MSA) a gagné en popularité ces dernières années, en raison de sa remarquable évolutivité, de sa compatibilité avec les environnements nuagiques et de son alignement sur les pratiques DevOps actuelles. Si l’adoption de la MSA s’avère simple pour les nouvelles applications, la migration de systèmes monolithiques existants vers l’architecture MSA est plutôt ardue. C’est là que notre solution MicroMiner entre en jeu : MicroMiner permet d’identifier les microservices dans les systèmes monolithiques par apprentissage machine. Pour ce faire, on analyse les relations entre les éléments du code et on extrait les informations sémantiques à même le code. Nous avons rigoureusement évalué la précision de MicroMiner pour des systèmes existants. Nous avons comparé les résultats aux normes et à d’autres approches de pointe. Nos résultats montrent que MicroMiner excelle dans l’automatisation de l’identification des microservices. Mots clés : Microservices, monolithe, architecture, migration, apprentissage machine
Migrer un logiciel monolithique vers des microservices
Un système monolithique existant est une architecture logicielle obsolète caractérisée par une base de code unique et vaste qui intègre toutes les composantes et fonctionnalités de l’application. Ces systèmes évoluent généralement au fil du temps, devenant de plus en plus complexes, englobant les interfaces utilisateur et la logique d’affaires à l’accès aux données, à même une base de code unifiée. Cette complexité rend leur entretien, leur modification et leur évolution difficile.
Conscientes de ces défis et du besoin de modernisation, les organisations envisagent souvent d’adopter un nouveau paradigme architectural, comme les microservices, visant ainsi une approche plus agile et modulaire de développement et de déploiement de logiciels. À l’opposé d’une grande application monolithique, l’architecture en microservices (MSA) permet de concevoir et d’organiser les applications logicielles sous forme de regroupement de petits services indépendants. Chacun de ces services, ou « microservices », assume des tâches précises et bien définies au sein de l’application. Plusieurs grandes organisations, comme Netflix, Amazon et eBay, ont déjà adopté ce style architectural en remaniant leurs systèmes d’affaires monolithiques. Cependant, une telle migration est coûteuse en temps et en ressources.
Une étude (Fritzsch, 2019) a porté sur la migration de 14 systèmes dans différents domaines, révélant le coût en temps et en ressources de la migration. Les délais allaient de 1,5 à plus de 3 ans pour achever une migration. Dans certains cas, les équipes de projet ont même compté jusqu’à 40 membres, reflétant un effort concerté pour accélérer le processus de migration.
Dans le but d’automatiser ce processus et d’en réduire les coûts, nous proposons l’approche appelée MicroMiner (Trabelsi 2022). Il s’agit d’une approche permettant d’identifier des microservices par types fondée sur l’apprentissage machine et les analyses sémantiques de façon à décomposer les systèmes logiciels monolithiques en microservices. Ces microservices respectent deux grands principes : la responsabilité unique et le couplage faible.
MicroMiner : un processus en trois phases
Nous présentons ici MicroMiner, un outil permettant l’identification automatique de microservices dans les systèmes logiciels monolithiques. On n’analyse que le code source de systèmes logiciels monolithiques orientés objet, éliminant ainsi le recours à d’autres artefacts qui peuvent s’avérer difficiles à trouver. La figure 1 donne un aperçu de l’approche que nous proposons.
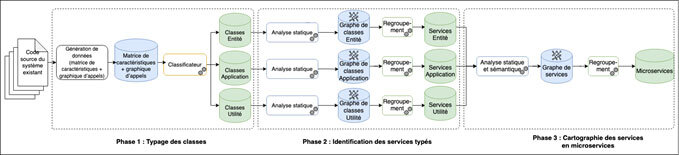
Figure 1 : Aperçu de l’approche MicroMiner
L’approche comprend trois phases :
- Typage des classes : l’objectif ici est de distinguer les classes dans le système logiciel monolithique en fonction de leurs rôles ou responsabilités. Nous avons eu recours à l’apprentissage machine pour catégoriser chaque classe, déconstruisant ainsi horizontalement le système en trois couches distinctes. Ce processus prédit et attribue des étiquettes à chaque classe, soit « Application » pour les classes de la couche Affaires, « Entité » pour celles de la couche Permanence et « Utilité » pour celles de la couche Utilité (illustré à la figure 2).
- Identification des services typés : dans la deuxième phase, nous avons identifié les services « Application », « Entité » et « Utilité », ou ce que nous appelons les services typés, en regroupant les classes dans chaque couche. Ce processus s’appuie sur le regroupement de graphes qui prend en compte les relations entre les classes.
- Cartographie des services en microservices : la dernière phase consiste à générer les microservices. Nous divisons le système selon les fonctionnalités (voir figure 2). Les services typés sont rassemblés en regroupement souple, où chaque élément peut appartenir à plusieurs groupes. Dans notre contexte, les éléments représentent les services, tandis que les groupes correspondent aux microservices. Les microservices sont déterminés en fonction (1) des relations entre les services et (2) du domaine d’application (limites du contexte). Chaque microservice peut consister en un ou plusieurs services d’application, d’entité et d’utilité.
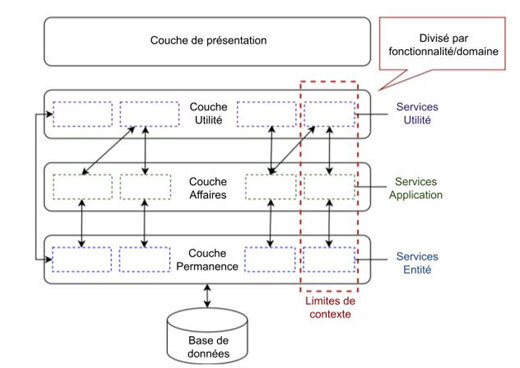
Figure 2 : Décomposition du logiciel
Évaluation objective de MicroMiner
Les résultats de notre approche ont fait l’objet d’un processus complet d’évaluation, d’après deux aspects principaux :
- Comparaison avec les approches de pointe : nous avons d’abord évalué la qualité de nos résultats en les comparant à ceux obtenus par deux méthodologies de pointe en identification de microservices. Cette comparaison rigoureuse nous a permis de mesurer l’efficacité de notre approche.
- Évaluation des mesures qualitatives: en plus des comparaisons quantitatives, nous avons effectué une évaluation approfondie à l’aide de mesures qualitatives afin d’examiner de plus près la qualité des microservices identifiés. Cette approche offre une perspective globale sur la qualité de nos résultats.
Nos études d’évaluation ont porté sur quatre systèmes logiciels différents, à savoir :
- Compiere : un vaste système ERP, comprenant un total de 1042 classes.
- JForum : un système de vente au détail en ligne de taille moyenne.
- PetClinic et POS : deux systèmes contenant moins de 100 classes chacun.
Pour garantir la fiabilité de notre approche, nous avons établi une vérité de base contre laquelle nous avons comparé nos résultats. En outre, nous avons mesuré la précision, le rappel et la F-mesure pour chaque système. Nos résultats démontrent notamment que MicroMiner excelle dans l’identification de microservices architecturaux pertinents. Cette méthode a atteint un taux de précision de 68,15 %, un rappel de 77 % et une F-mesure remarquable de 72,1 %, surpassant les deux autres approches de pointe.
Conclusion
Nous avons présenté ici MicroMiner, une approche prometteuse conçue pour identifier les microservices dans les systèmes logiciels monolithiques au moyen de l’apprentissage machine. MicroMiner plonge profondément dans les bases de code, identifie des types de services distincts et examine soigneusement les relations entre les composants. Les tests exhaustifs que nous avons effectués sur quatre systèmes existants soulignent son efficacité, atteignant un taux de précision d’environ 72 %.
Avec MicroMiner, nous façonnons une vision de l’avenir où les systèmes logiciels incarnent naturellement la modularité, l’évolutivité et l’agilité, permettant ainsi leur adaptation transparente aux besoins évolutifs des utilisateurs. Notre objectif premier est de minimiser les coûts de migration, encourageant les entreprises à adopter des architectures plus souples et, par conséquent, à fournir des solutions logicielles conviviales et des plus efficaces. Par contre, le travail est loin d’être terminé. Nous sommes déterminées à automatiser d’autres aspects du processus de migration, notamment la génération de composants spécifiques aux microservices et l’optimisation des procédés de déploiement.
Complément d’information
Pour plus d’informations sur le sujet, lire l’article suivant : Trabelsi, Imen, et al. « From legacy to microservices: A type‐based approach for microservices identification using machine learning and semantic analysis. » Journal of Software: Evolution and Process (2022): e2503.


