
L’IA pour l’inspection par drones des tours de téléphonie mobile

Achetée sur Gettyimages. Droits d’auteur.
L’inspection aérienne des tours de téléphonie mobile est maintenant essentielle en raison de plusieurs facteurs critiques. Selon la Federal Communications Commission, les tours de téléphonie cellulaire doivent être inspectées régulièrement, particulièrement avec l’essor de la 5G, où encore plus d’antennes et de sites cellulaires doivent être inspectés régulièrement. Ces inspections ne concernent pas seulement les défauts mécaniques, électroniques et structurels, mais également la vérification des actifs, la gestion des stocks et la géocartographie pour l’installation de nouveau matériel.
Les inspections manuelles traditionnelles de tours de 30 à 300 mètres de haut sont jalonnées de risques. Elles ont entraîné de nombreux accidents, faisant notamment des blessés graves et des morts. De plus, les inspections manuelles sont coûteuses (de 900 $ à 5 000 $ par pylône), chronophages et donnent souvent des données incomplètes [1].
Aussi, les drones peuvent servir à collecter des données sur différents sites. Pour pouvoir guider les drones en conduite autonome, ceux-ci doivent comprendre l’environnement. À cette fin, nous proposons un localisateur d’objets peu coûteux pour guider le drone dans ses déplacements autonomes en inspections aériennes, offrant une alternative plus sécuritaire, rentable et efficace à l’inspection manuelle des tours de téléphonie cellulaire. Le localisateur fournit des données et des analyses de qualité qui aident le personnel au sol à garantir l’intégrité et la fonctionnalité du réseau mondial de tours de téléphonie mobile, laquelle ne cesse de croître et de se complexifier. L’inspection aérienne n’est pas seulement une tendance, mais un développement essentiel dans le maintien et l’expansion de l’infrastructure de communication moderne.
Pour former notre localisateur, il nous faut des données annotées par l’humain (boîtes autour de la tour objet et autres objets). Nous proposons donc d’entraîner les localisateurs à l’aide de pseudo-étiquettes provenant d’un modèle de vision autosupervisé [2]. Cependant, comme ces modèles (transformateurs autosupervisés) décomposent la scène en cartes contenant des parties d’objets et ne dépendent d’aucun signal de supervision explicite, ils ne peuvent faire la distinction entre l’objet d’intérêt et les autres, comme l’exige le modèle WSOL. Nous proposons donc d’exploiter les multiples cartes générées par les têtes de transformeur pour obtenir des pseudo-étiquettes destinées à l’apprentissage profond du WSOL.
Problème d’annotation des localisateurs d’objets
Les réseaux neuronaux profonds ont atteint des performances impressionnantes dans diverses tâches de vision par ordinateur, comme la détection et la localisation d’objets [3]. Cependant, l’apprentissage des réseaux neuronaux profonds nécessite des annotations de boîtes englobantes qui indiquent l’emplacement d’un objet d’intérêt. L’annotation de ces objets avec boîtes englobantes est à la fois coûteuse et chronophage, car elle nécessite l’expertise d’annotateurs humains [3]. Nous proposons donc une nouvelle approche capable d’apprendre sous faible supervision : utiliser des étiquettes d’image pour décrire les objets d’intérêt et apprendre à prédire les boîtes englobantes de ces objets dans les images, comme l’illustre la figure ci-dessous. Plus précisément, nous présentons une méthode permettant de récolter des pseudo-étiquettes à partir de réseaux neuronaux profonds autosupervisés, qui serviront ensuite à former notre localisateur d’objets.
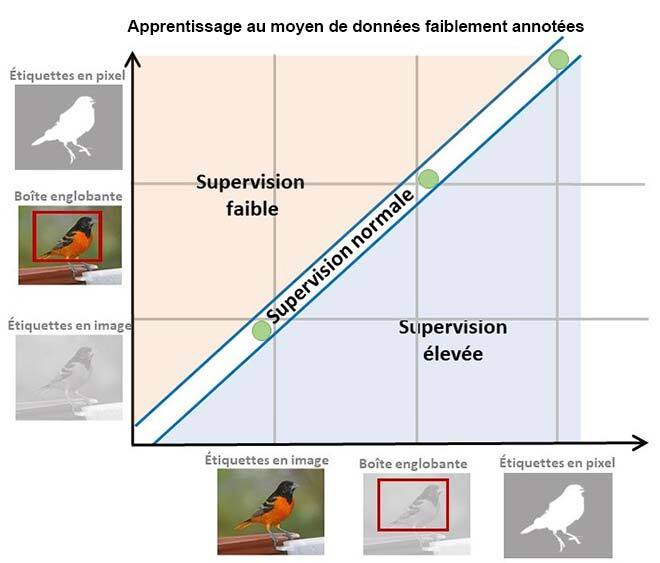
Figure 1: Paradigme d’apprentissage faiblement supervisé
La création des pseudo-étiquettes
Pour obtenir des pseudo-masques de vérité terrain (pseudo-GT), nous avons d’abord extrait diverses cartes d’attention-activation de réseaux neuronaux (des transformateurs), entraînés de manière autosupervisée, sans utiliser d’étiquettes d’image. Ces cartes nous ont permis d’identifier des propositions d’objets comme objet d’intérêt. En outre, ces cartes d’attention étant formées de valeurs continues, nous les avons converties en régions binaires et avons délimité les propositions d’objets. Ensuite, nous avons utilisé chacune de ces propositions d’objets pour générer de nouvelles images augmentées ou perturbées en appliquant des techniques floues aux zones situées en dehors des régions identifiées.
Toutes les images augmentées ou perturbées ont été soumises à un classificateur préentraîné, et les cartes les plus performantes avec les scores de classification les plus élevés ont été sélectionnées comme pseudo-étiquettes. Ensuite, une carte parmi les N cartes sélectionnées a servi à l’échantillonnage de quelques pixels pour les régions en avant-plan et en arrière-plan selon leurs valeurs d’activation. Ces pseudo-pixels ont ensuite servi à entraîner notre réseau de localisation, aidant ainsi le drone à identifier les objets d’intérêt. De plus, l’entraînement avec seulement quelques pseudo-pixels a permis au réseau d’explorer différentes parties de l’objet [3, 4]. Cette méthodologie d’apprentissage nous a permis d’éliminer le recours aux experts humains pour annoter les objets d’intérêt dans les images individuelles.
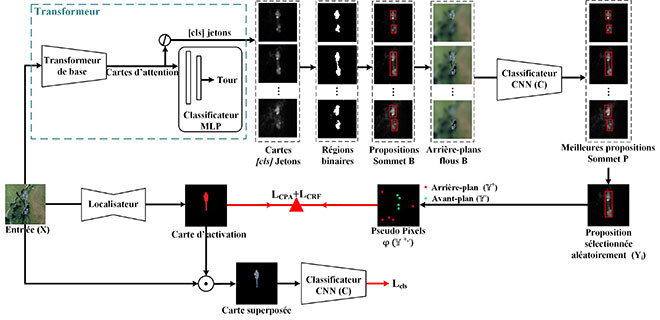
Figure 2: Illustration du diagramme du système
Résultats et conclusion
Notre méthode a atteint des performances de pointe dans les tâches de localisation de tours comparativement aux méthodes de référence, comme le montre la figure ci-dessous. En outre, notre modèle peut réduire efficacement le bruit et est capable de générer des cartes avec des boîtes plus nettes que les cartes d’attention servant à récolter des pseudo-étiquettes dans la formation de notre localisateur. En plus de ces résultats, nous avons mené des expériences avec le jeu de données CUB-200-2011 et démontré que notre modèle s’adapte très bien à d’autres domaines pour la localisation d’un objet d’intérêt.
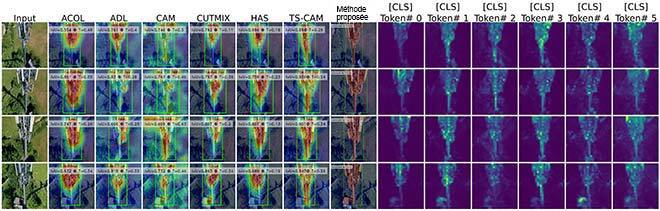
Figure 3: Résultats de notre modèle sur l’ensemble de données TelDrone
Complément d’information
Voyez les résultats détaillés, l’analyse et le cadre expérimental dans notre article : Discriminative Sampling of Proposals in Self-Supervised Transformers for Weakly Supervised Object Localization. Le code permettant de reproduire nos résultats est disponible en ligne gratuitement à :
https://github.com/shakeebmurtaza/dips.
Pour plus d’information, veuillez consulter l’article.


