
Détection faiblement supervisée de tableaux par boîtes englobantes

Achetée sur Istockphoto.com. Droits d’auteur
Les tableaux de manuscrits anciens : une mine d’informations
Les documents historiques contiennent des informations historiques de plusieurs domaines de recherche. La rareté de ces documents, s’ils subissent des dommages, expose les informations qu’ils contiennent à une perte irrémédiable. Pour préserver et récupérer certaines des parties les plus importantes de la vaste quantité d’informations contenue dans ces documents, nous nous sommes penchés sur la détection des pages qui contiennent des tableaux.
Ces éléments graphiques sont très utiles aux scientifiques pour acquérir des informations essentielles sous forme abstraite. Cette tâche est classée dans le domaine de la détection d’objets, lequel a récemment connu des progrès avec l’avènement des algorithmes d’apprentissage profond. L’un de ces algorithmes est le Faster RCNN [1] que nous avons combiné avec un filtre de prétraitement Gabor [2], l’extraction faiblement supervisée par boîtes englobantes [3] et un pseudo-étiquetage pour relever les défis suivants :
- haute généralisation de la détection d’images de tableaux parmi 32 millions de données d’images;
- détection de tableaux de structures variées (figure 1);
- données étiquetées insuffisantes pour la phase d’entraînement des algorithmes d’apprentissage profond.

Figure 1. Exemples de tables dans des documents historiques
Le filtre de Gabor
Dans la première étape de la conception de notre système, nous avons appliqué le filtre de Gabor pour :
- rendre le jeu de données plus compatible avec l’architecture Faster-RCNN;
- obtenir une meilleure discrimination entre l’objet cible (tableau) et les autres parties de l’image en exagérant l’écart ou le fond blanc entre le texte et les tableaux;
- supprimer le bruit visuel, comme les taches d’encre.
La figure 2 montre l’image prétraitée avec le filtre de Gabor.

Figure 2. Image traitée avec le filtre de Gabor
Termes et définitions
Dans cette recherche, nous avons utilisé deux sources de documents historiques numérisés :
- ECCO : Eighteenth-Century Collections Online (ECCO) est une énorme collection de documents historiques comptant plus de 32 millions de pages. Selon la chronologie des données collectées, ECCO est divisée en ECCO1 et ECCO2.
- NAS : Cet ensemble de données contient environ 0,5 million d’images de documents numérisés provenant d’une période plus longue qu’ECCO (1666 à 1916).
Pour cette tâche de détection binaire, nous avons défini deux étiquettes :
- Tableau : présentation de données importantes sous forme de texte ou de chiffres en lignes et colonnes résumant l’information de manière compacte.
- Non-tableau : toutes les images de documents numérisés sans tableau, comme diagrammes, illustrations, cartes et images sur une page blanche ou une page avec texte (figure 3).

Figure 3. Exemples de non-tableau dans des documents historiques
Faster-RCNN
L’algorithme Faster-RCNN a servi de module principal de détection d’objets dans notre recherche en raison de ses caractéristiques et de nos ensembles de données. En effet, il a permis :
- une meilleure performance sur les images à faible résolution;
- une détection d’objets de grande et de petite taille;
- un meilleur équilibre entre vitesse et précision.
Extraction faiblement supervisée de boîtes englobantes
Pour être performant, un modèle Faster-RCNN doit être entraîné avec des données correctement étiquetées, les objets entourés de boîtes englobantes. Mais l’étiquetage manuel des données et l’extraction des boîtes englobantes sont des procédés coûteux. Pour résoudre ce problème, nous avons instauré dans nos recherches une technique d’extraction de boîtes englobantes faiblement supervisée (figure 4), une approche d’apprentissage automatique en spirale. Elle se compose des cinq phases suivantes :
Phase 1 : entraîner et biaiser le modèle de détection de tableaux;
Phase 2 : tester le modèle biaisé précédent sur les non-tableaux; sortie : des boîtes englobantes faibles pour les non-tableaux;
Phase 3 : entraîner avec deux étiquettes : tableaux avec boîtes englobantes précises et non-tableaux avec boîtes englobantes faibles;
Phase 4 : pseudo-étiquetage – test sur des données non étiquetées pour augmenter notre ensemble d’entraînement;
Phase 5 : entraîner – réentraîner le modèle en ajoutant les données de l’étape précédente.
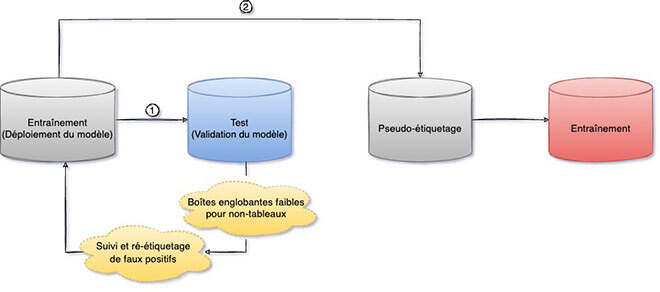
Figure 4. Extraction de boîtes englobantes faiblement supervisée
Résultats
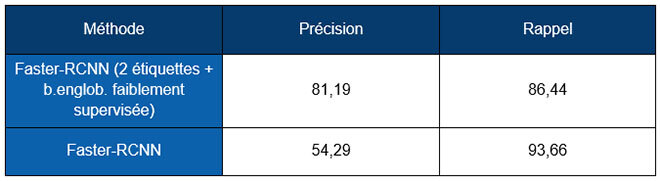
Nous avons comparé le modèle Faster-RCNN avec et sans l’extraction faiblement supervisée des boîtes englobantes en utilisant les sous-ensembles de données ECCO (mélange de ECCO1 et ECCO2) et NAS.
Table 1 Résultats du modèle Faster-RCNN avec et sans l’extraction de la boîte englobante
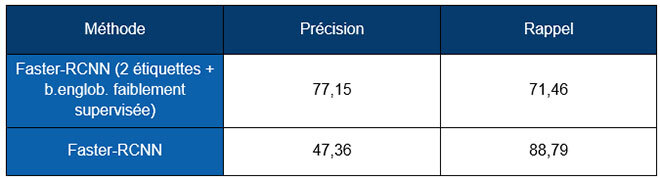
Table 2 Résultats du modèle Faster-RCNN avec et sans extraction faible de la boîte englobante sur le sous-ensemble de données NAS
Pour détecter toutes les images avec tableaux, nous avons appliqué notre modèle à trois ensembles de données différents, comprenant 32 millions d’images au total (figure 5).
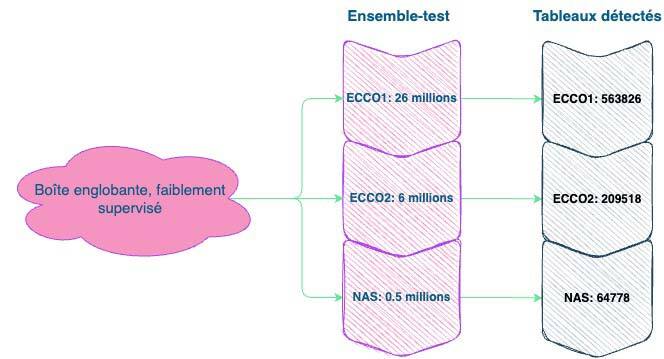
Figure 5. Résultats de notre modèle
Conclusion
En tirant parti du filtre de Gabor et de l’extraction de boîtes englobantes faiblement supervisée, nous avons préparé de meilleures données d’entrée et suffisamment de boîtes englobantes autour des objets cibles pour la phase d’apprentissage, ce qui a permis d’obtenir des performances élevées à faible coût. Il s’agit également d’une méthodologie généralisée et robuste pour détecter des tableaux avec dispositions diverses parmi 32 millions d’images de documents historiques numérisés.
Le coût élevé de l’extraction des boîtes englobantes et la fiabilité des performances sur des ensembles de données non équilibrés sont deux défis communs à la plupart des tâches d’apprentissage automatique, ce que nous avons résolu par une approche d’apprentissage en spirale avec la technique d’extraction de boîtes englobantes faiblement supervisée.
Complément d’information
Pour plus d’informations sur cette recherche, veuillez lire l’article suivant :
Samari, A., Piper, A., Hedley, A., Cheriet, M. (2021). Weakly Supervised Bounding Box Extraction for Unlabeled Data in Table Detection. In: , et al. Pattern Recognition. ICPR International Workshops and Challenges. ICPR 2021. Lecture Notes in Computer Science(), vol 12667. Springer, Cham. https://doi.org/10.1007/978-3-030-68787-8_25


