
27 novembre 2018

La description d’images sert généralement en pratique clinique à évaluer le déclin cognitif des patients. Cet article présente notre approche computationnelle pour évaluer automatiquement les performances de patients âgés décrivant une image. Notre approche mesure la quantité d’informations que les patients peuvent tirer de l’image et la pertinence de leurs descriptions. Elle fournit également une évaluation des modifications subtiles du langage que les chercheurs cliniques considèrent comme étant des signes de troubles cognitifs. Cette évaluation peu coûteuse et non invasive nous a permis d’identifier jusqu’à 85 % des patients atteints de la maladie d’Alzheimer, même à un stade précoce. Mots clés : maladie d’Alzheimer, détection précoce, description d’images, analyse automatique, traitement des langages naturelles, couverture d’information, altérations du langage, Le voleur de biscuits.
Introduction
Bien qu’étant la forme de démence la plus répandue, la maladie d’Alzheimer (MA) est généralement diagnostiquée plusieurs années après son apparition. La recherche de biomarqueurs permettant de détecter la MA plus tôt avance à grande vitesse [1], mais l’acquisition de certains biomarqueurs existants, par extraction du liquide céphalo-rachidien ou par imagerie par résonance magnétique (IRM), peut être coûteuse et invasive pour cette population déjà vulnérable. Il est donc important d’utiliser des biomarqueurs, non pas comme outils de surveillance courants, mais pour faciliter le diagnostic des patients chez lesquels on soupçonne fortement la maladie. Mais comment dépister les patients présentant des signes précoces de MA à l’aide d’outils peu coûteux et non invasifs?

Figure 1 Perte de mémoire
Plusieurs tests cognitifs sont couramment utilisés en pratique clinique pour dépister les patients. Un des tests les plus faciles pour les patients est la description d’images. En effet, le patient n’a qu’à décrire ce qui se passe dans l’image qui lui est présentée avec le plus de détails possible. Nous proposons ici une méthodologie pour évaluer automatiquement la description d’une image, tâche qui peut être adaptée à différentes populations.
Méthodes et résultats
Ensemble de données
Nous avons utilisé la base de données Pitt Corpus [2] de DementiaBank. Cet ensemble de données comprend 542 transcriptions et enregistrements audio de patients décrivant l’image Le voleur de biscuits [3] (voir figure 2). De cet ensemble de données, nous avons tiré 25 transcriptions de sujets sains pour servir de référent. Ce référent nous a servi à évaluer 517 transcriptions : 257 participants atteints de la MA, 217 témoins en bonne santé et 43 personnes présentant un déficit cognitif léger (DCL). Le DCL est une forme de déficit qui n’affecte pas la vie quotidienne d’une personne ; c’est souvent un stade très précoce de la MA.
Mesure de couverture d’information
Pour évaluer la description d’une image, le clinicien mesure la quantité et la qualité des informations que le patient donne durant sa description. Cette description est notée en fonction d’une liste prédéfinie d’éléments de référence que l’évaluateur considère comme « importants » à mentionner. Cette liste peut être tirée de la documentation ou définie par l’évaluateur même. Toutefois, les listes établies par les experts ne sont pas normalisées et ne couvrent pas nécessairement les observations du point de vue d’une population plus âgée. Nous considérons que le meilleur référent pour le dépistage de cette population est une population en bonne santé présentant des caractéristiques similaires.

Figure 3 Patiente en train de décrire une image
Dans cet article, nous proposons une méthodologie adaptée de la mesure de couverture d’information proposée par Velázquez [5], créant automatiquement un référent qui permet d’évaluer la couverture d’information dans les transcriptions. Ce référent comprend les éléments mentionnés par 25 participants en bonne santé lors de la description de l’image Le voleur de biscuits.
Nous nous sommes inspirés de Velázquez [5] pour établir une mesure de couverture d’information bidirectionnelle : nous avons testé a) combien d’éléments du référent ont été mentionnés par le participant (informativité) ; et b) combien d’éléments mentionnés par le participant se retrouvent dans le référent (pertinence).
Caractéristiques linguistiques
De nombreuses études ont démontré que la langue est l’une des premières capacités cognitives à changer en raison de la MA [6]. Ces changements, au début, sont très subtils et peuvent passer inaperçus. Toutefois, une analyse computationnelle peut révéler des indices statistiques significatifs menant à des mécanismes d’alerte précoce relative à la maladie. Plusieurs caractéristiques phonétiques et linguistiques — mesures de la richesse du vocabulaire, du débit, des conjonctions et des prépositions, et mesures des signaux audio — nous ont servis à évaluer les propriétés linguistiques des descriptions.

Figure 4 Communication
Classification automatique
À partir de deux algorithmes d’apprentissage machine, SVM (Machine à vecteurs de support) et RF (Forêt d’arbres décisionnels) nous avons classifié l’ensemble de données et constaté à quel point nous pouvions automatiquement distinguer les sujets sains des patients MA et DCL sur la base de nos évaluations automatiques. Notre système présente une sensibilité de 85 % dans la détection des patients MA et DCL en combinant les caractéristiques linguistiques et la mesure proposée de couverture d’information (voir la figure 5).
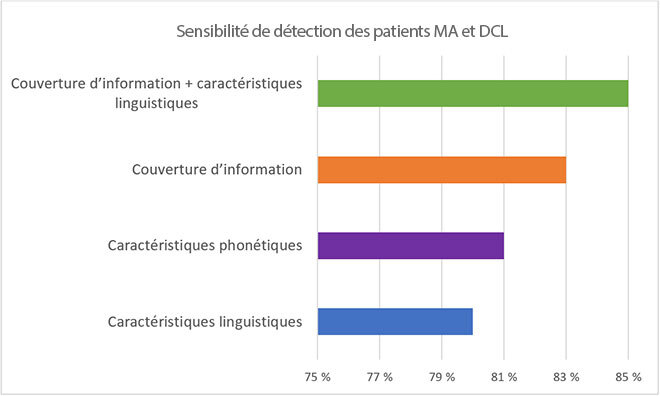
Figure 5. Sensibilité des algorithmes d’apprentissage automatique à détecter la maladie d’Alzheimer et le déficit cognitif léger, lorsque formés à partir de différentes caractéristiques. Les meilleurs résultats ont été obtenus en combinant les caractéristiques linguistiques et notre mesure proposée de couverture d’information.
Conclusion
Bien que la description de l’image donne un aperçu des capacités cognitives des patients, elle doit être complétée par un ensemble d’examens cognitifs qui évaluent différents aspects de la cognition du patient, comme le langage et l’attention. Aussi, les populations de différents niveaux d’instruction et milieux sociodémographiques pourraient se concentrer leurs observations sur des caractéristiques différentes.
Notre méthode peut facilement être adaptée à différentes populations. Elle se base sur un test clinique déjà établi et largement utilisé, peu coûteux et non invasif, et l’amène plus loin encore. Dans un seul test, nous pouvons évaluer automatiquement l’informativité et la pertinence de la description d’une image ainsi que les fonctions langagières du patient, établissant ainsi une description plus complète de certaines de ses fonctions cognitives.
Information supplémentaire
Pour plus d’information sur cette recherche, veuillez consulter l’article suivant :
Hernández-Domínguez, L. ; Ratté, S. ; Sierra-Martínez, G.; Roche-Bergua, A. 2018. “Computer-based evaluation of Alzheimer’s disease and mild cognitive impairment patients during a picture description task.” Alzheimer’s & Dementia, 10, pp. 260–268.


