
19 novembre 2025

La revue de code est essentielle au développement de logiciels modernes. Mais les changements de code ne sont pas tous traités de la même façon. Par exemple, les corrections de bogues urgentes reçoivent souvent la même attention que les mises à jour esthétiques. Les outils traditionnels utilisent des règles rigides basées sur des mots-clés pour identifier l’objectif des changements de code, entraînant souvent des erreurs de classification. Dans cet article, nous présentons le LLMCC (Large Language Model Change Classifier), un outil d’IA utilisant de grands modèles de langage (LLM) pour comprendre l’intention derrière les changements de code. Testé sur trois grands projets à code source ouvert, le LLMCC surpasse largement les systèmes basés sur des règles et les modèles d’IA traditionnels. Cet outil promet d’aider les équipes de développement à hiérarchiser plus efficacement leurs efforts de revue et à améliorer la qualité des logiciels.
MOTS-CLÉS : grands modèles de langage, revue de code moderne, apprentissage machine, analyse des intentions de changement
Repenser la revue de code avec l’IA
Le développement de logiciels modernes est un travail d’équipe. Avant d’être acceptés dans un projet, les nouveaux codes sont soumis à une revue, au cours de laquelle un autre membre de l’équipe évalue les changements afin de détecter les bogues ou d’identifier les améliorations possibles. Mais les changements de code ne se valent pas tous. La correction d’un bogue critique est plus urgente que la mise à jour de la documentation ou l’ajout d’une nouvelle fonctionnalité. Malheureusement, la plupart des systèmes de revue traitent tous les changements de la même manière, ce qui peut retarder des corrections importantes. C’est là que les grands modèles de langage (LLM) entrent en jeu.
Les limites de la classification traditionnelle
Les équipes de développement peuvent marquer manuellement leurs changements de code avec des étiquettes telles que « correction de bogue », « fonctionnalité » ou « test ». Cependant, cette méthode est incohérente et souvent omise. Des recherches antérieures ont tenté d’automatiser cette classification à l’aide de règles basées sur des mots-clés [1]. Mais cette approche est trop rigide. Un changement de code qui améliore la documentation peut inclure le mot « améliorer », incitant le système à la classer à tort comme une nouvelle fonctionnalité.
LLMCC : classification plus intelligente des changements de code
Pour résoudre ce problème, nous avons développé le LLMCC (LLM Change Classifier), un outil qui exploite les LLM pour comprendre et classer l’intention derrière les changements de code. Contrairement aux méthodes traditionnelles, le LLMCC tient compte du titre du changement, de sa description, des fichiers concernés et même des différences de code. Il fonctionne avec Gemini 1.5 Pro [2] de Google.
Le LLMCC fonctionne en mode zero-shot, ce qui signifie qu’il ne nécessite pas de données d’entraînement étiquetées. Il peut faire des prédictions en se basant uniquement sur sa compréhension des langues naturelles et des langages de programmation.
Comment le LLMCC surpasse les méthodes existantes
Nous avons évalué le LLMCC à l’aide de 935 changements de code réels provenant de trois grands projets à code source ouvert : Android, OpenStack et Qt. Nous avons comparé les prédictions du LLMCC avec les heuristiques traditionnelles [1], l’apprentissage machine standard [3] et les modèles d’apprentissage profond tels que BERT [4] et RoBERTa [5].
Le LLMCC a systématiquement surpassé toutes les autres techniques dans tous les projets. Il a obtenu des scores F1 jusqu’à 33 % supérieurs à ceux des approches basées sur des règles et a montré une amélioration de 77 % du MCC, comme illustré à la figure 1. Nous pouvons également voir à la figure 2 que le LLMCC a surpassé les algorithmes d’apprentissage profond (BERT et RoBERTa). Ces résultats soulignent la capacité du LLMCC à comprendre à la fois le langage naturel et le code.
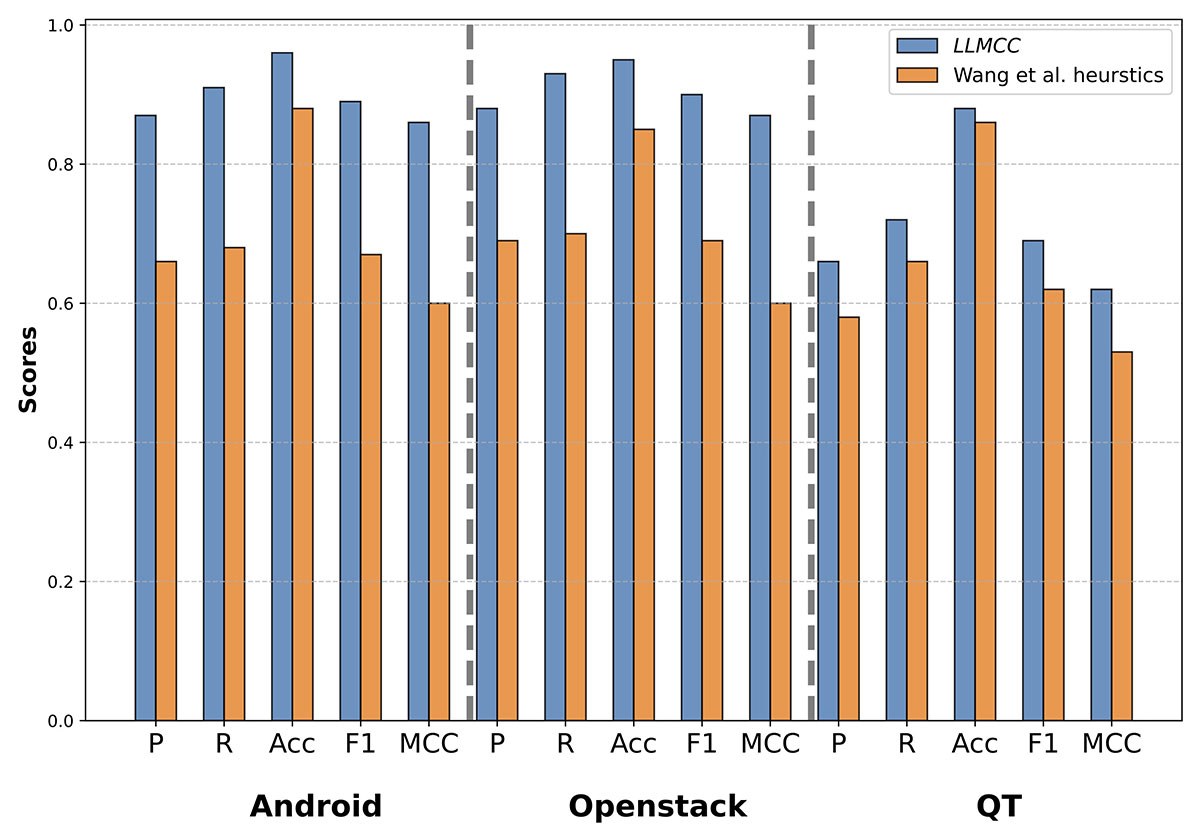
Fig. 1. LLMCC c. heuristiques de Wang et al. [1].
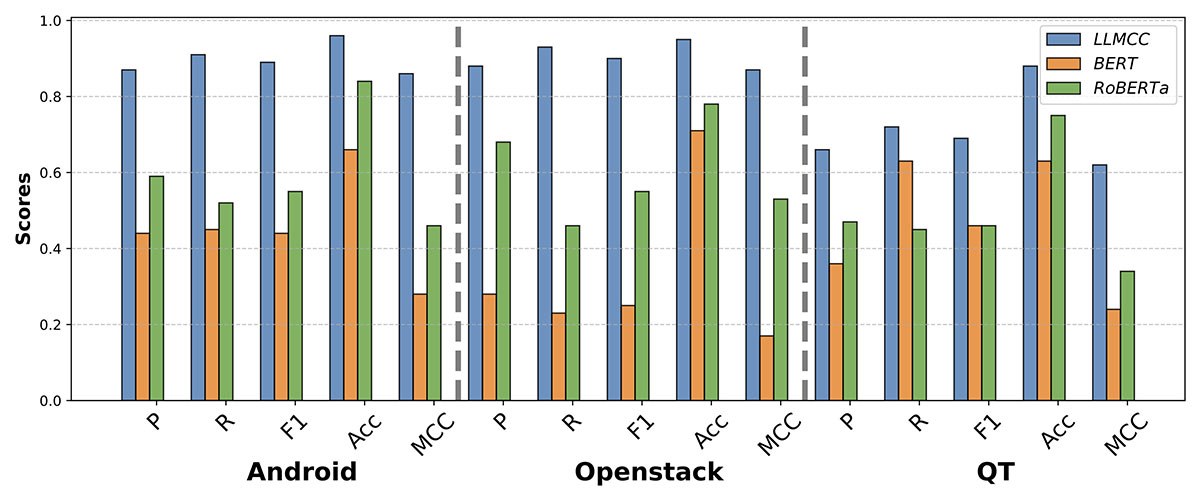
Fig. 2. LLMCC c. BERT et RoBERTa.
Revues plus rapides, hiérarchisation améliorée
Le LLMCC rationalise le processus de revue de code en permettant une meilleure hiérarchisation. Plutôt que de traiter tous les changements de code de la même manière, on peut se concentrer sur les mises à jour urgentes ou importantes. Par exemple, une correction critique peut être identifiée et revue plus rapidement, ce qui réduit le risque de retards.
Les travaux futurs auront pour but d’expérimenter différents LLM (libres c. propriétaires), d’améliorer l’ingénierie des invites [6] et d’étudier dans le monde réel l’intégration dans les flux de développement.
Conclusion : des revues de code plus intelligentes
La revue de code est essentielle au développement de logiciels, mais les méthodes actuelles peuvent être lentes et incohérentes. Avec le LLMCC, nous démontrons que les grands modèles de langage peuvent comprendre le code et son contexte, pour classifier précisément les intentions de changement, gagner du temps et améliorer la qualité des logiciels.
Informations supplémentaires
Oukhay, I. Chouchen, M. Ouni A. Fard Hendijani F. On the Performance of Large Language Models for Code Change Intent Classification. (SANER 2025, ERA track)
Chouchen, M. Oukhay, I. Ouni A. Learning to Predict Code Review Rounds in Modern Code Review Using Multi-Objective Genetic Programming (GECCO 2025)
RÉFÉRENCES
[1] S. Wang, C. Bansal, and N. Nagappan, “Large-scale intent analysis for identifying large-review-effort code changes,” Information and Software Technology, vol. 130, p. 106408, 2021.
[2] T. G. et al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,” arXiv preprint arXiv:2403.05530, 2024.
[3] A. Hindle, D. M. German, M. W. Godfrey, and R. C. Holt, “Automatic classification of large changes into maintenance categories,” in ICPC, 2009.
[4] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” NAACL, 2019.
[5] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
[6] M. Chouchen, N. Bessghaier, A. Ouni, and M. W. Mkaouer, “How do software developers use chatgpt? an exploratory study on github pull requests,” in MSR, 2024.


